
SPEECH PROCESSING: Music Genre Classification
gio



Summary
Portfolio ini dikerjakan untuk melengkapi nilai UAS course Speech Processing yang saya ikuti. Adapun studi kasus yang diambil yaitu pengklasifikasian genre musik dengan melakukan figur ekstrasi dari data suara menggunakan pemrograman Python. Hasil analisa dan pemrograman yang diterapkan disini diambil dari salah satu tugas paper yang saya kerjakan. Beberapa metode yang akan dijelaskan disini diantaranya:
- Membaca data suara dengan format .wav
- Ekstraksi fitur low dan high level dengan library librosa
- Implementasi Machine Learning untuk klasifikasi genre Musik dengan library scikit-learn
Description
DESCRIPTION
Pada project kali ini, saya menerapkan ekstraksi fitur yang mana merupakan salah satu tugas dari course “Speech Processing” yang saya ikuti. Adapun proses yang akan dirangkum di dalam portfolio ini yaitu : dataset genre musik, metod fitur ekstraksi, low dan high level feature, dan melakukan praktek dengan python. Selain melakukan ekstraksi fitur suara, saya juga akan membuat model machine learning untuk mengklasifikasikan genre musik.
DATASET
Dataset yang digunakan berasal dari data open source kaggle yang mana memiliki jumlah file 10.000 dengan 10 genre lagu. Adapun tipe dari data yaitu unstructured data karena data berupa suara dengan format wav. Untuk mempermudah kegiatan analisa, data - data suara tersebut akan dikelompokkan berdasarkan genre, lalu dilakukan ekstraksi.
Genre musik yang dimiliki dataset sangat beragam dan banyak dari segi jumlah. Untuk bisa membuat program berjalan lancar, maka dari itu genre musik hanya akan disisakan menjadi tiga saja yaitu genre pop, rock, dan disco. Pemilihan genre tersebut didasari oleh karakter masing-masing berbeda.
FEATURE EXTRACTION
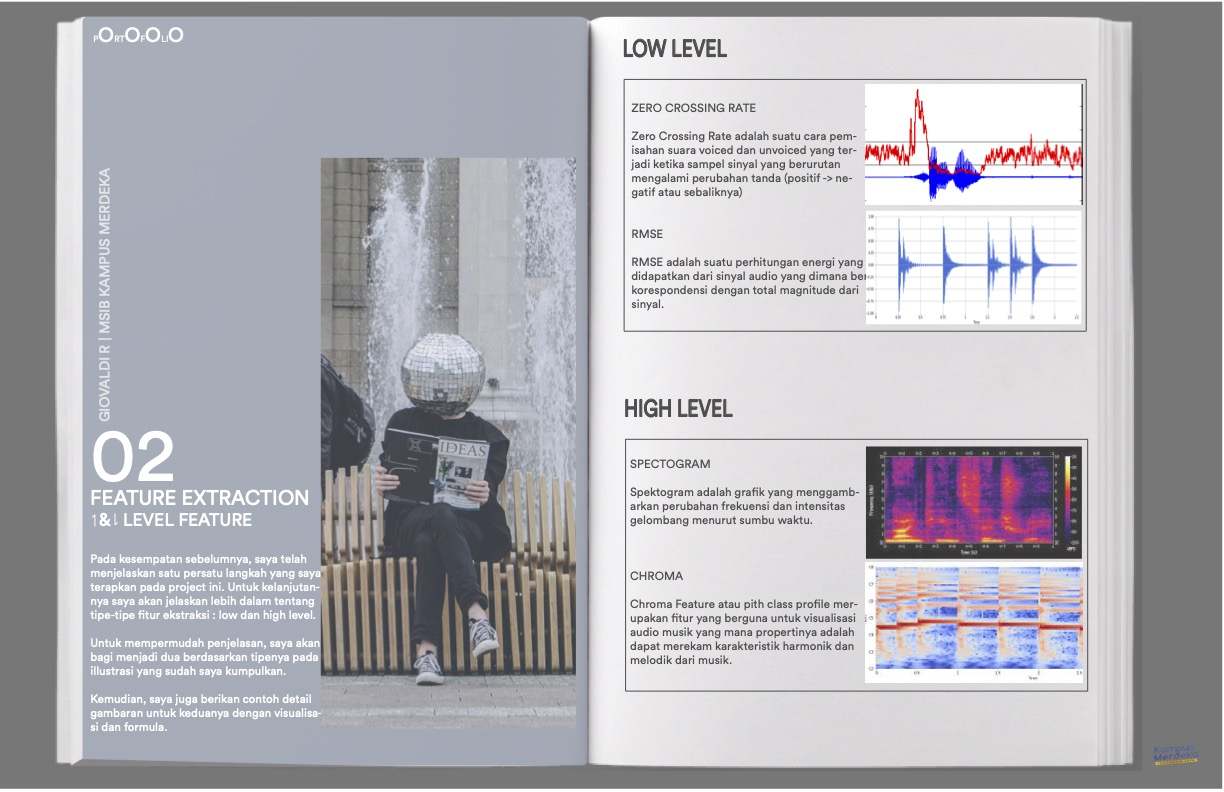
LOW LEVEL
Zero Crossing Rate adalah suatu cara pemisahan suara voiced dan unvoiced yang terjadi ketika sampel sinyal yang berurutan mengalami perubahan tanda (positif -> negatif atau sebaliknya)
RMSE adalah suatu perhitungan energi yang didapatkan dari sinyal audio yang dimana berkorespondensi dengan total magnitude dari sinyal.

HIGH LEVEL
Spektogram adalah grafik yang menggambarkan perubahan frekuensi dan intensitas gelombang menurut sumbu waktu.
Chroma Feature atau pith class profile merupakan fitur yang berguna untuk visualisasi audio musik yang mana propertinya adalah dapat merekam karakteristik harmonik dan melodik dari musik.

MACHINE LEARNING
Metode yang digunakan dalam machine learning adalah menggunakan klasifikasi. Secara singkat, setelah saya mendapatkan beberapa insight dari kegiatan feature extraction kedepannya, data tersebut akan di simpan dalam bentuk csv untuk dokumentasi serta untuk dilakukan permodelan dengan beberapa algoritma diantaranya Logistric Regression, SVM, KNN, RandomForest, Decision Tree, Gradient Boosting, Gaussian, XGB Classifier

Hasil akhir yang saya dapati adalah Model dengan akurasi tertinggi adalah RandomForest dengan nilai akurasi 99%.
Informasi Course Terkait
Kategori: Speech ProcessingCourse: Feature Extraction Speech
