
Scraping Website bisa.ai dengan Python
Arief Rachman Hakim

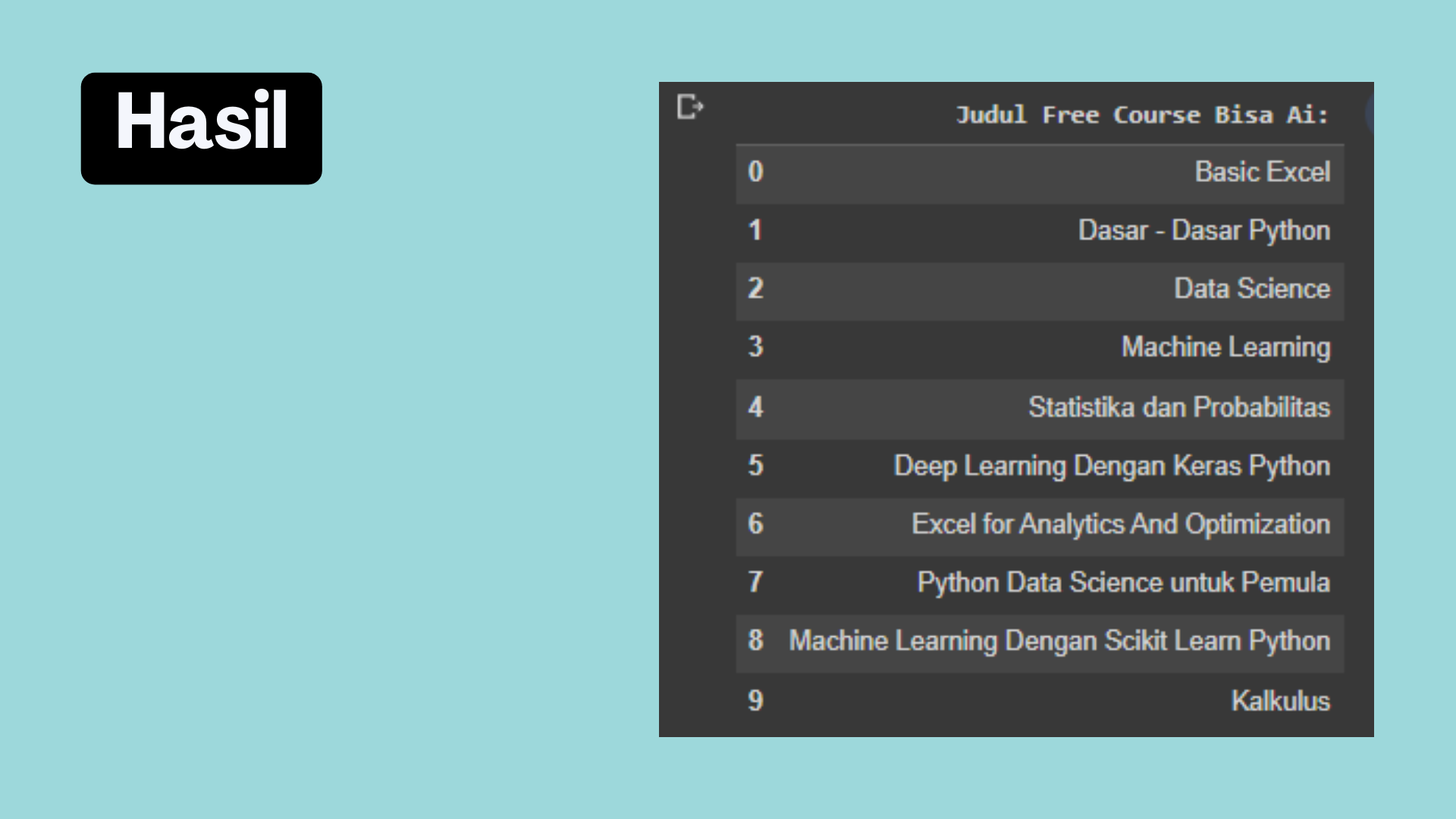

Summary
Kebutuhan akan data merupakan sebuah tantangan untuk analisis data. Seperti yang kita tahu terkadang resource big data atau data yang sangat banyak seperti kaggle tidak bisa memenuhi keginginan kita. Hal ini biasanya diakibatkan tingkat keunikan data yang kita perlukan yang sangat tinggi sehingga diperlukan data mining terhadap sumber yang relevan untuk kebutuhan analisis data kita. Salah satu metode yang dipakai adalah Web Scraping. Secara ringkasnya, Web Scraping adalah kegiatan pengambilan data dari sebuah website. Pada kesempatan kali saya akan melakukan web scraping terhadap https://bisa.ai/course/all_course/1
Description
Website target :
https://bisa.ai/course/all_course/1
Library yang dipakai :
- selenium
- chromium-chromedriver (driver)
- sys
- bs4
- pandas
Tutorial :
1. Install library dan driver browser

update terlebih dahulu sistem cloud linux agar bisa menginstall driver browser

Driver ini berguna untuk kebutuhan library selenium

2. Import Library
Mencari lokasi dari Driver browser yang sudah diinstall pada cloud colab adalah ‘/usr/lib/chromium-browser/chromedriver’



3. Melakukan scraping
Proses pertama adalah menginisialisasi website target, selanjutnya gunakan driver browser dengan selenium untuk mengakses file dokumen websiter tersebut. Dengan bantuan beautifulSoup kita dapat mendapatkan file dokumen website untuk targeting letak data yang akan diambil.

Idenfikasi file dokumen website bisa.ai

Terdapat Script javascript sehingga kita tidak bisa melakukan copy text dan inspect dengan bantuan mouse dan kombinasi keyboard

Ditemukan class dari file dokumen html yang menyimpan data yang kita perlukan yaitu pada div dengan class = ‘card shadow box-shadow pointer mb-2’

4. Targeting div yang mengandung data

Ditemukan bahwa data yang kita perlukan terletak pada h5 dengan class = ‘card-title’

5. Menyimpan data yang diperlukan

6. Menyimpan data menjadi DataFrame serta mengekspornya menjadi file csv

Membuka file yang sudah diekspor

hasil

7. Dokumentasi Kode
https://drive.google.com/drive/folders/1GKWoo_8vFCGQqiw5sKJf_yoIwWEwvKSd?usp=sharing
Informasi Course Terkait
Kategori: Data Science / Big DataCourse: Information Retrieval for Beginner
