
Sentimen Analysis Ulasan Shopee App with LSTM
Arief Rachman Hakim


Summary
Ulasan dari sebuah aplikasi adalah sebuah kunci dari bagaimana kesuksesan kinerja dari aplikasi tersebut untuk memenuhi kebutuhan user. Oleh karena itu, kita sebagai developer harus aware terhadap kolom ulasan dari aplikasi yang telah kita buat untuk sebagai feedback fitur mana saja yang harus diimprove lagi. Pada kesempatan kali ini, saya akan mempraktekkan sentiment analysis dari sebuah dataset ulasan aplikasi shopee dari google play store yang sudah saya scraping dengan lstm. Untuk proses scraping saya akan menaruhnya pada portofolio information retrieval agar lebih sesuai dengan course yang dibahas. Untuk proses sentiment analysis dengan lstm tersendiri ada beberapa tahap yaitu preprocessing data text, pembuatan kamus kata dengan word2vec, dan melatihanya dengan neural network lstm
Description
Dataset yang digunakan dan resource lain :
https://drive.google.com/drive/folders/1WZS64KYehMKalLAuGVM8dyNSdgqpLAxi?usp=sharing
Library yang dipakai :
- pandas
- numpy
- nltk
- sklearn
- re
- joblib
- gensim
- keras
- matplotlib
Tutorial :
1. Import Gdrive

2. Import Library

Mendowload sejumlah package tambahan dari library nltk

3. Membaca data dari Gdrive

Dataset terdiri dari 2 fitur yaitu ulasan dan label, kondisi dataset sudah dilakukan pelabelan Positive dan Negative

4. Data Preprocessing
Proses yang dilakukan pada tahap ini adalah Filtering, Casefolding, dan Stopwords removal

Hasil dari data yang sudah melalui preprocessing

5. Split Data
Split data menjadi data train dan test

identifikasi data train

identifikasi data test

6. Membuat Kamus Kata dengan Word2Vec
Pada tahap ini membuat variable yang bernama documents yang berisi text dari fitur ulasan, selajutnya documents akan diproses menjadi word2vec model

Setelah model word2vec dibuat, selanjutnya kita identifikasi berapa panjangnya dan lakukan training agar membentuk semantik

Pada proses ini adalah Idenfikasi kata-kata yang mirip dari kata yang diinputkan

7. Membuat token dari fitur ulasan

Identifikasi panjang data yg sudah melalu tokenizing adalah 5311

8. Penerapan padding pada variable X untuk Ekstrasi Fitur


9. Melakukan Label Encoder dari variable y
Pada proses ini akan merubah data label yg sebelumnya Negative dan Positive menjadi Numerik yaitu 0 & 1

10. Membuat Embedding Layer dengan data yang sudah di tokenizing dan vocab dari Word2Vec Model

11. Pembuatan Arsitektur LSTM
Pada model LSTM yang saya buat menggunakan Sequential dengan penambahan embedding layer, Dropout, dan activationnya sigmoid


Selajutnya model dicompile dengan optimizer adam dan metrics nya accuracy karena ini adalah termasuk klasifikasi

Training model dengan batch_size 1024 dan epochs 20

12. Visualisasi Proses yang terjadi



13. Evaluasi Model
Membuat function agar kita dapat melakukan evaluasi model menggunakan data yang kita inputkan .
Untuk cara kerjanya function preprocessingData() akan melakukan preprocessing data text yang kita inputkan sehingga bentuknya menjadi vector. Selanjutnya data vector tersebut akan dilakukan prediksi dengan function predictionData() melalui model yang sudah kita latih.

Hasilnya data yang kita inputkan menghasilkan prediksi yang cukup akurat

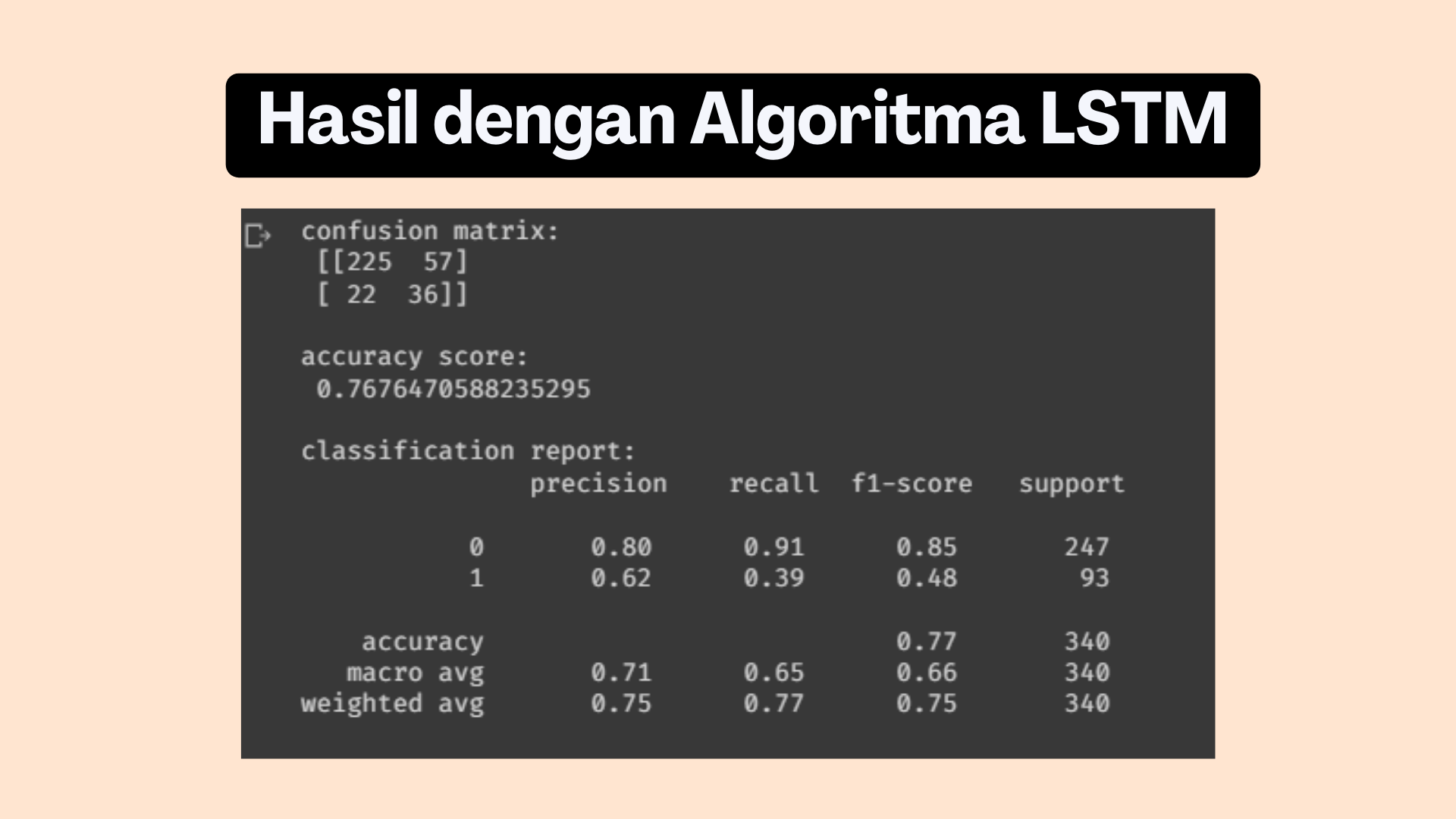
Melakukan evaluasi model dengan bantuan confusion matrix

Hasil akhir dengan confusion matrix untuk model yang telah dibuat adalah 77%

14. Dokumentasi Kode
https://drive.google.com/drive/folders/1WZS64KYehMKalLAuGVM8dyNSdgqpLAxi?usp=sharing
Informasi Course Terkait
Kategori: Natural Language ProcessingCourse: Dasar Pemrograman Natural Language Programming dengan Python
