
Klasifikasi Penguin dengan Random Forest
Arief Rachman Hakim



Summary
Penguin atau pinguin (ordo Sphenisciformes, famili Spheniscidae) adalah hewan akuatik jenis burung yang tidak bisa terbang dan secara umum hidup di belahan Bumi selatan (Wikipedia). Dengan berbagai macam spesies yang ada maka pada kesempatan kali ini saya akan membuat sebuah klasifikasi penguin dengan algoritma Random Forest. Dalam dataset ini terdapat tiga jenis penguin yaitu Adelie, Chinstrap, dan Gentoo.
Description
Dataset yang digunakan :
https://github.com/mwaskom/seaborn-data
Library yang digunakan :
- pandas
- numpy
- seaborn
- matplotlib
- warnings
- sklearn
Deskripsi Dataset :
Dalam dataset ini terdiri dari tiga spesies yaitu Chinstrap, Gentoo, dan Adelie

Dalam dataset ini juga terdapat ciri-ciri dari penguin yang dijabarkan menjadi :

Tutorial :
1. Import Library

2. Menggunakan Dataset dari Seaborn yang terdapat dokumentasi di https://github.com/mwaskom/seaborn-data

3. Load dataset

4. Mengetahui Shape dari dataset

5. Mengidentifikasi value yang null

6. Mengidentifikasi tipe data dari dataset

7. Visualisasi data dari berbagai fitur



8. Menghapus value yang null dari fitur

9. Mengidentifikasi berapa jumlah value yang null

10. Menyalin dataset untuk persiapan Split data

11. Mengidentifikasi dataset, diketahui masih ada yang bertipe object, sehingga nanti akan dilakukan encoding data

12. Fitur spesies akan digunakan sebagai Variable dependen ( Y )

13. Mengubah spesies diubah menjadi tipe data Integer

14. Setelah fitur spesies sudah disimpan pada variable Y, Kita akan drop fitur spesies

15. Selajutnya kita akan memfilter fitur sex yang berisi tentang female dan male

16. Fitur female akan didrop, maka kita akan menggunakan definisi ketika Male sama dengan 1

17. Mengidentifikasi fitur island yang unik

18. Selanjutnya fitur island akan diencode dengan Label encoder sehingga tipe data akan diubah menjadi Integer

19. Mengidentifikasi hasil data yang sudah diproses

20. Buat variable baru yang menyatukan fitur yang sudah diencode

21. Setelah fitur sex tadi sudah diencode menjadi Male, maka akan didrop

22. Tipe data fitur di hasil akhir

23. Tipe data variable dependen ( Y ) bertipe Integer dan variable independen X akan menyimpan data yang sudah diencode sebelumnya

24. Melakukan Split data dan training data dengan algoritma Random Forest

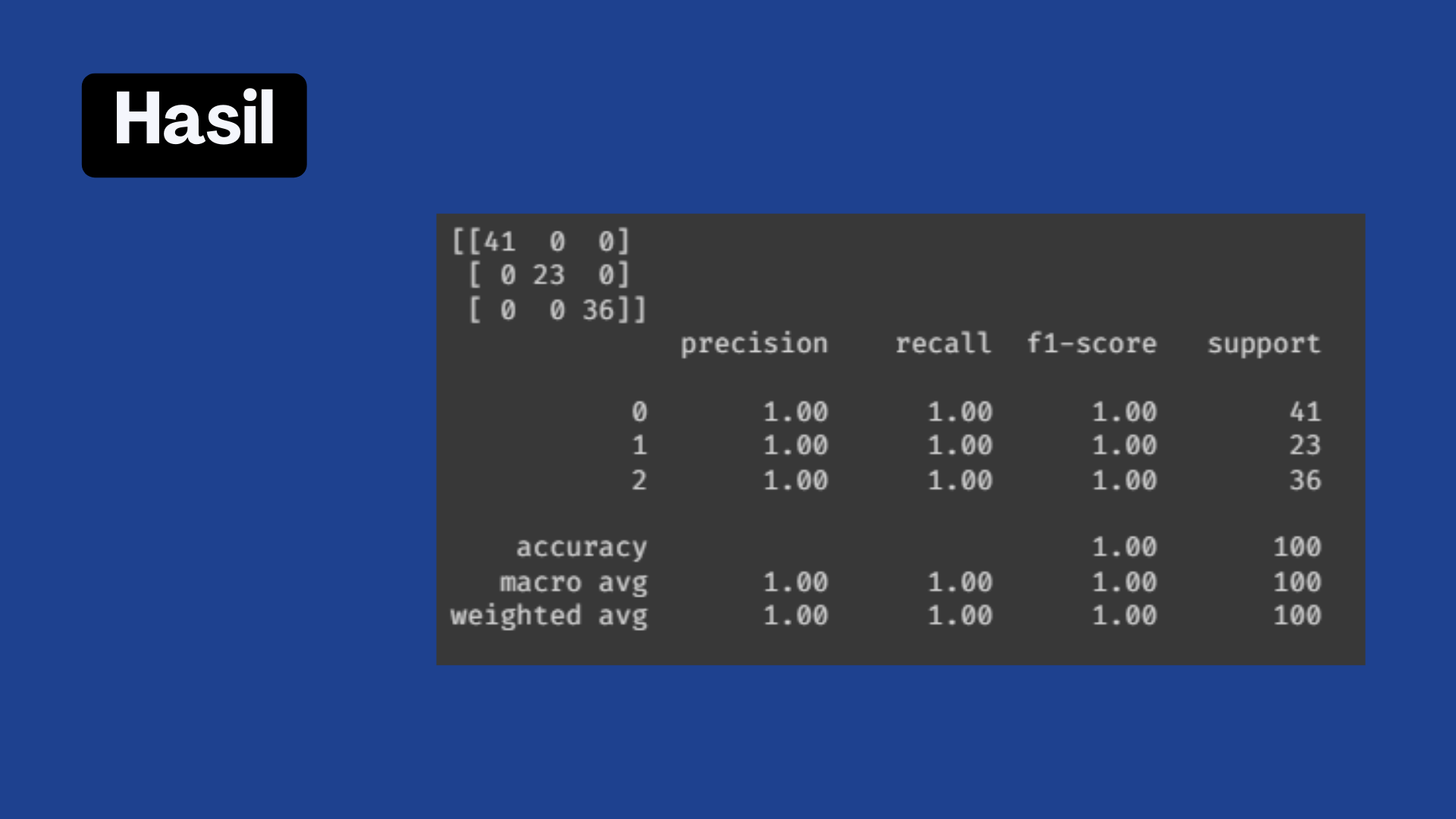
25. Evaluasi Model dengan mendapatkan akurasi sebesar 100%

26. Mengetahui fitur dari variable X untuk melakukan prediksi

27. Melakukan prediksi dengan data yang kita inputkan sesuai dari urutan fitur pada data X
Dapat diketahui prediksi menghasilkan bahwa spesies dari data yang diinputkan adalah Chinstrap

28. Dokumentasi Kode
https://drive.google.com/drive/folders/1SJwutGu1BFibDJPmlKRByC-1Q1out0RU?usp=sharing
Informasi Course Terkait
Kategori: Data Science / Big DataCourse: Data Science



