
Phishing Web Detection based on Machine Learning
Dhimaz Purnama Adjhi


Summary
Phishing Attack is one of the cyberattacks that utilizes email text messages, social media, SMS, and telephone to trick victims into providing sensitive user data in the form of system login credential information, credit card details, and so on. This cyberattack is one of the oldest cyberattacks that first appeared in the 1990s, until now Phishing Attack is still one of the most destructive cyberattack techniques with its various execution methods becoming increasingly sophisticated [1]. There are many types of Phishing Attacks to trick victims, until now there are more than 5 circulating in cyberspace, one of which is Spear, Whaling, Vhishing, Smishing, Angler, and so on [2]. According to the APWG (Anti-Phishing Working Group), in the second quarter of 2022 observed the occurrence of phishing attacks of various types with a total of more than 1,097,811 occurring in cyberspace, this number is a new record and the worst in the quarter of 2022 [3].
In a Phishing Attack, the perpetrator will disguise himself as a legal institution and send a message or command containing a website URL page to the individual victim that has been designed in such a way that it looks very professional and similar to the original [1]. Even perpetrators can target a group of victims such as companies to direct them to the Website URL page containing automatic malware installation to freeze a system network as part of a massive group sensitive data information disclosure attack that exists on the environmental network [2]. It can be said, Phishing Attack is basically a type of cyberattack that is included in the category of Social Engineering Attack, this type of attack is not launched by utilizing security loopholes in a system or network, but by exploiting the psychological aspects of the victim. Perpetrators who carry out phishing attacks will interact and communicate directly with the victim, then take advantage of their lack of understanding or awareness of the dangers of providing sensitive data information.
To solve this problem, I created a classification system to detect indications of phishing elements on a website page based on machine learning. The classification system in it uses technology such as Pandas, Numpy, Scikit-learn, Wordcloud, Seaborn, Matplot, and so on. The dataset obtained to support this machine learning system uses sources from kaggle and row data in it amounting to 549,345 in the form of various kinds of Website Page URLs that are indicated by phishing and are not indicated by phishing [4]. The main part of this classification system uses the extraction of features of each word character in the URL dataset and later each character of the word will be collected based on its label. After which it is processed using a count vector before being processed using the Logistic Regression model. The accuracy results achieved in the classification system managed to reach 96% and the machine learning model has been wrapped and stored in the form of a “.pkl” extension for further deployment needs, such as the application of website or application-based phishing detection. The creation of the classification system is expected to be useful for people who are unfamiliar with the world of technology and can minimize the occurrence of phishing attacks for people who are unfamiliar with cyberspace.
Description

To create a classification model for detecting phishing indications on a website page based on machine learning, it would be nice to first know a little about the structure URL or what parameters can cause a website to be indicated by phishing. In the world of cyber security, we can actually find out the classification of detection of phishing indications through the URL (Uniform Resource Locators). We can observe that the website pages indicated by phishing in it are as follows:
- Have an Abnormal URL.
An abnormal URL is a condition where the URL has a structural subdomain and an unclear path, for example: "https.paypal.web.site/?=%dhiqwdcvv/login.php."
- Unprofessional Domains
URLs that have an unprofessional domain can be categorized as an indication of phishing, fraudsters will usually imitate the URL as the original and will not be able to use a professional domain such as ".com" because it is expensive and slots that are full or have been used by the original for their use, usually unprofessional domains can be found with examples: ".xyz", ".site", ".online", and ".me".
- URLs Still Use IP Addresses
In modern times like this, it is quite strange that a website does not use DNS (Domain Name System), it is suspected that this can trigger indications of phishing.
- Does Not Use HTTPS (Hypertext Transfer Protocol Secure) Protocol 443
To provide security to its users, usually large sites that are genuine or credible will use SSL for their websites, Most phishing websites do not have an SSL (Secure Sockets Layer) Certificate [5].
- Has a Word Character At The End Of The Path Like the ".exe" file extension.
This can be a prelude to the spread of malware on devices to steal all important data information.
- Use the URL Shortening Service.
It is necessary to be aware when many fake links are hidden through URL shorteners under the guise of shortened links or the like.
From what structure or parameters can cause a website to be indicated by phishing, we can create a machine learning model and train it based on a collection of every word character in the URL datasets with a good or bad URL label. The initial step is of course we will create a new column to divide or separate each word character on the URL label, after which it is visualized using wordcloud and sorted by label.
There is a flow of stages that need to be passed to build a model for a website detection system for phishing pages using machine learning. The stages in creating a machine learning model are as follows:

Preliminary Preparation & Import All Required Libraries
To support a web phishing detection classification system based on machine learning, it is necessary to have a technology or library framework in its design that suits the needs of each functionality. A framework is a framework used to develop a system more easily. The framework libraries that I used in creating this system are as follows:
- Drive, use for connecting Google Collab to Google Drive
- Pandas, use for data manipulation and analysis
- Numpy, use for multi-dimensional array and matrix
- Seaborn, use for high-level interface for drawing attractive and informative statistical graphics
- Matplotlib, used to perform data visualizations such as plotting graphs for one or more axes.
- Time, use for calculate time in process
- Scikit-learn, used to help process data or conduct data training for machine learning needs in this system.
- LogisticRegression, algorithm use to predict good or bad
- Train_test_split, splitting the data between feature and target
- classification_report, gives whole report about metrics (e.g, recall, precision, f1_score, c_m)
- confusion_matrix, gives info about actual and predict
- CountVectorizer, create sparse matrix of words using regexptokenizers
- make_pipeline, use for combining all preprocessors techniques and algorithms
- NLTK, digunakan untuk membangun program analisis teks
- RegexpTokenizer, regexp tokenizers use to split words from text
- SnowballStemmer, use for stemmes words
- Wordcloud, use to visually display text data
- Image, use to getting images in notebook
- Pickle, use to dump model

Get Datasets Collection from Kaggle
I'm using datasets from kaggle, with an owner named Tarun Tiwari. It has a usability of 10.00 and the datasets are licensed to open datasets and have a ".csv" extension. Data contains 549.346 entries, there are two columns. Label column is prediction col which has 2 categories, Good - which means the URLs are not containing malicious stuff and this site is not a Phishing Site, and Bad - which means the URLs contains malicious stuff and this site is a Phishing Site. I saved the datasets into my google drive, which will then be processed into google collab. The sources of these datasets are as follows:
https://www.kaggle.com/datasets/taruntiwarihp/phishing-site-urls

Data Preprocessing
Data preprocessing is an initial technique to convert raw data into cleaner information and can be used for subsequent processing. This process can also be called the first step to retrieve all available information by checking, cleaning, filtering, visualizing, and changing the shape of the dataset format into a form that can be easily understood by the machine. At this stage, I found that the datasets obtained had no missing value and the datasets had an object data type with the ratio of the good url and bad url labels was 4 to 1.5.

After that, I did a filter to remove the word characters with "www." and "https" from the Datasets column of the URL. The reason I do this is because www is actually a sub domain itself and while the https word character I omit is because in URLs with bad labels or URLs with indications of phishing often disguised by slippage of the word https character which does not refer to the protocol itself, but only as phishing. It is evident in the datasets that I use that there are such cases and they are quite a lot.


For example, when I do testing inputting "https://google.com", the system will later detect that the URL has an indication of phishing or bad where the actual URL is that there is no indication of phishing or good. It can happen that the machine has matched what they learned in the datasets and matched each character of the word. Therefore, I wouldn't need the word characters (www.) and (https) as the determinant parameters for the presence of phishing indications. By using such a concept, the problem can minimize the occurrence of false negatives.


Next, I will do a clumping of each word character for further processing in analyzing what parameters indicate that the URL is labeled bad or phishing. My first step is to create 3 new columns as parameters to analyze in the URL, the first one we do first is the division or separation of each word character in the URL column using the help of RegexpTokenizer and create a new column named "text_tokenized" to enter the value.

The second step we do steamed text with the help of SnowballStemmer and create a new column named "text_steamed" to enter its value, It is the process of reducing the word to its word stem that affixes to suffixes and prefixes or to roots of words known as a lemma. In simple words stemming is reducing a word to its base word or stem in such a way that the words of similar kind lie under a common stem. Stemming is important in natural language processing (NLP). For example, cared becomes care, fairly becomes fair.

The third step we do is finishing by separating the commas and creating a new column named "text_sent" to enter the values.

Then the next stage is to visualize the data. First of all, we group the character set of words in the "text_sent" column based on the label. Then Visualize some important keys using word cloud by creating a function, requiring additional help such as images to be able to visualize images properly.






After that the last stage of data preprocessing is to change the form of the dataset format into a form that is easily understandable to the machine. In this case CountVectorizer is used to transform a corpora of text (text_sent URL) to a vector of term / token counts.

Split Data
The method of dividing the data into two or more parts that make up the data subset. Generally, data splitting separates two parts, the first part is used to evaluate or test the data (Test) and the other data is used to train the model (Train). In this case, I did a split for the dependent variable X as the feature/text_sent and the independent variable Y as the label.

Build & Train Model, Test Model
We'll create a machine learning model and train it using Logistic Regression. Logistic Regression is a Machine Learning classification algorithm that is used to predict the probability of a categorical dependent variable.

It was found that we got a test data score of 96%, a pretty good score for machine learning models to detect the classification of phishing indications from a website page.
Make sklearn pipeline using Logistic Regression
Use machine learning pipeline (sklearn implementations) to automate most of the data transformation and estimation tasks. Machine Learning (ML) pipeline, theoretically, represents different steps including data transformation and prediction through which data passes. The outcome of the pipeline is the trained model which can be used for making the predictions. Load Save Model in the form of the extension ".pkl".


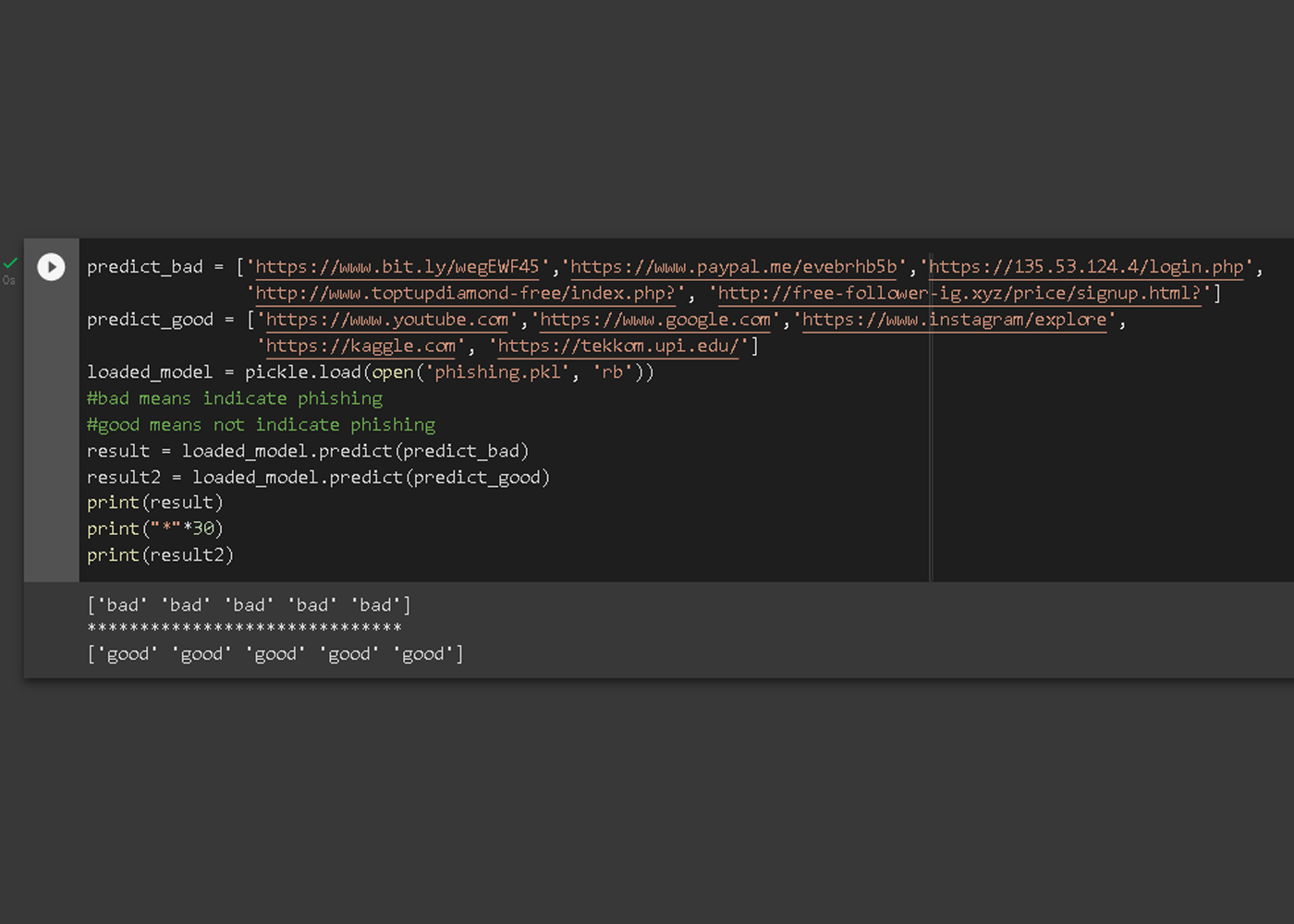
Test some links URL website page in model saved “phishing.pkl” to see if the model gives good predictions. We also prepare several website page URL links that will be predicted to have indications of phishing (bad) and have no indication of phishing (good).
predict_bad =
'https://www.bit.ly/wegEWF45'
'https://www.paypal.me/evebrhb5b'
'https://135.53.124.4/login.php'
'http://www.toptupdiamond-free/index.php?'
'http://free-follower-ig.xyz/price/signup.html?'
predict_good =
‘https://www.youtube.com'
'https://www.google.com'
'https://www.instagram/explore'
https://kaggle.com'
'https://tekkom.upi.edu/'

It can be seen that the test results using non-datasets have been successful and in accordance with predictions. Finally, we have been able to create a classification system for detecting phishing website page based on machine learning. Furthermore, the load save model "phishing.pkl" can be improved into a combination of systems such as websites or applications which we will later integrate in terms of back-end for the machine learning model in creating a phishing detection system in a website or application. The flowchart in the phishing website page classification detection system that we will make is as follows:

Reference
[1] https://glints.com/id/lowongan/phishing/
[2] https://www.goldenfast.net/blog/phishing-adalah/
[3] https://apwg.org/trendsreports/
[4] https://www.kaggle.com/datasets/taruntiwarihp/phishing-site-urls
[5] https://blogs.masterweb.com/apa-itu-phising/
[6] https://www.hostinger.co.id/tutorial/apa-itu-url
[7] https://vitalflux.com/sklearn-machine-learning-pipeline-python-example/
[8] https://yunusmuhammad007.medium.com/3-machine-learning-evaluation-239426e3319e
[9] https://www.datacamp.com/tutorial/wordcloud-python
[10] https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression
Dhimaz Purnama Adjhi - Studi Independen Batch 3
AI Infra - Tugas Sertifikasi AIBIZ
Informasi Course Terkait
Kategori: Artificial IntelligenceCourse: Infrastuktur Kecerdasan Artifisial (SIB AI-INFRA)
