
KLASIFIKASI DATA MODEL RANDOM FOREST REGRESSION
AMALYA MIFTAHUL JANNAH


Summary
SUMMARY
Klasifikasi data adalah proses untuk memprekdisi suatu kategori data dengan teknik menggelompokan data berdasarkan keterikatan data terhadap sampel yang telah ada.
Description
DESCRIBTION
Dalam Klasifikasi data menggunakan Machine Learning, dataset yang diolah bisa diperoleh dari Kanggle.com dengan data yang disajikan merupakan data gaji karyawan berdasarkan jabatannya, guna memprediksi tingkat kejujuran calon pegawai dalam memberikan informasi mengenai gajinya di perusahaan sebelumnya.
Berikut tampilan implementasi praktik klasifikasi data menggunakan source code Random Forest Regressor secara keseluruhan:

Langkah – Langkah pengklasifikasian data menggunakan Machine Learning pada Google Colaboratory:
- Langkah pertama dalam mengklasifikasikan data yaitu adalah mengimport library yang diperlukan.

- Selanjutnya kita Impor dataset yang telah disiapkan, kemudian definisikan variabel independen X dengan melakukan slicing.

- Lalu import Library untuk membuat model random forest regession dari sklearn. Untuk parameter yang dibuat adalah n_estimator sebanyak 10 buah, dimana presikdi yang dibuat nantinya berjumlah 10 dan akan dihitung meannya. Mengaplikasian model ke dataset menggunakan regressor.fit(x,y)

- Mempresiksi variabel dependen Y
- Prediksi yang dihasilkan adalah kode yang menunjukan nilai variabel dependen Y adalah x=6,5, dimana jika nilai Y_pred dieksekusi maka menghasilkan nilai 167.000 dollar pertahun. Dengan demikian hasil yang ditunjukkan terbilang cukup baik karena sangat dekat dengan datasetnya.

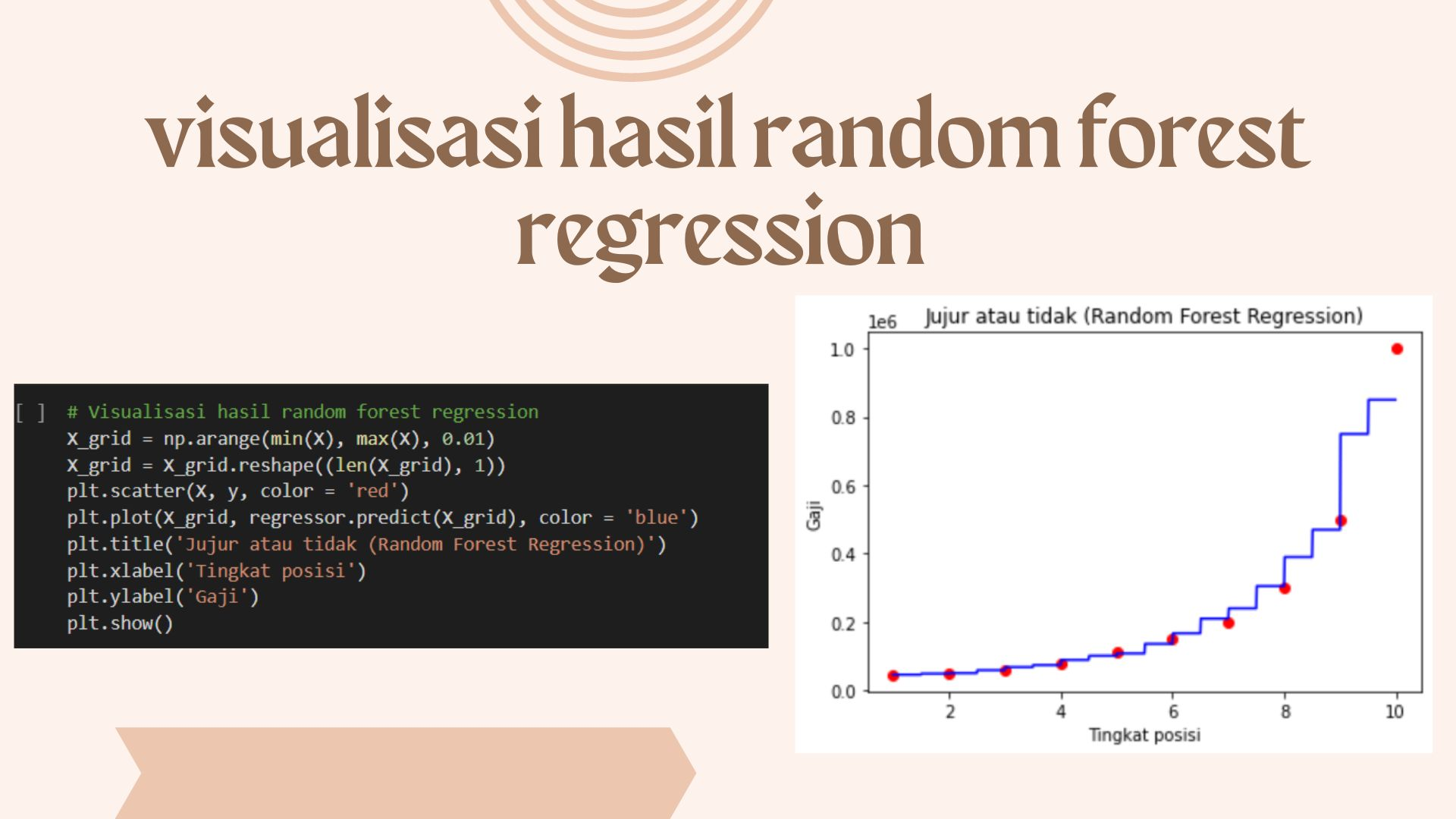
- Visualisasi hasil


Dalam penggunaan model random forest regression yang dibuat adalah hasil dari 10 decision tree, di mana ditunjukan semakin banyak data anak tangga maka menggambarkan semakin banyak pula interval pembagiannya/ semakin banyak pembagian cabang keputusan yang dibuat. Kemudian dari sisi prediksi dengan y_pred pada model random forest hasilnya juga sangat dekat dengan data setnya yairu 167.000 dollar/tahun . Hal tersebut bisa dikatakan random forest lebih presisi karena lebih dekat diangka 175.000 dollar/tahun jika dibandingkan dengan 1 decisoin tree yaitu 150.000 dollar/tahun.
Informasi Course Terkait
Kategori: Data Science / Big DataCourse: Data Science
