
Classification Milk Quality using SVM, KNN, and DT
Yuliana


Summary
Pada pembelajaran ini saya menggunakan Jupyter Notebook dan bahasa pemograman python sebagai tools dalam mengklasifikasian data brain stroke. Saya melakukan klasifikasi pada data menggunakan algoritma KNN, Decision Tree, dan Support Vector Machine (SVM). Saya mengambil data set dari Kaggle.com bernama “Milk quality” https://www.kaggle.com/datasets/yrohit199/milk-quality
Description
Melakukan klasifikasi pada data menggunakan algoritma KNN, Decision Tree, dan Support Vector Machine (SVM). Saya mengambil data set dari Kaggle.com bernama “Milk quality” https://www.kaggle.com/datasets/yrohit199/milk-quality
- Load Data dan Preprocessing
Hal pertama yang harus dilakukan yaitu download dataset lalu upload pada jupyter notebook, setelah itu melakukan import library yang dibutuhkan. Saya menggunakan library pandas, numpy, matplotlib, dan seaborn. Selanjutnya membaca dataset yang bernama brain_stroke.csv menggunakan perintah .read_csv() dan .head(), data yang akan ditampilkan yaitu 5 baris data teratas.

Menggunakan perintah .info() untuk mengetahui infromasi dari setiap kolom, dan perintah .shape() untuk mengetahui ukuran data berapa jumlah baris dan kolom.


Menggunakan perintah .isnul().sum() untuk mengecek apakah ada missing value pada data atau tidak.


Diatas saya melakukan perubahan value pada kolom grade, dimana pada kolom ini awalnya berisikan value high, medium, dan low. Lalu saya merubah value nya menjadi 2, 1, dan 0.
- Visualisasi Data


- Training Data

- Modelling Data
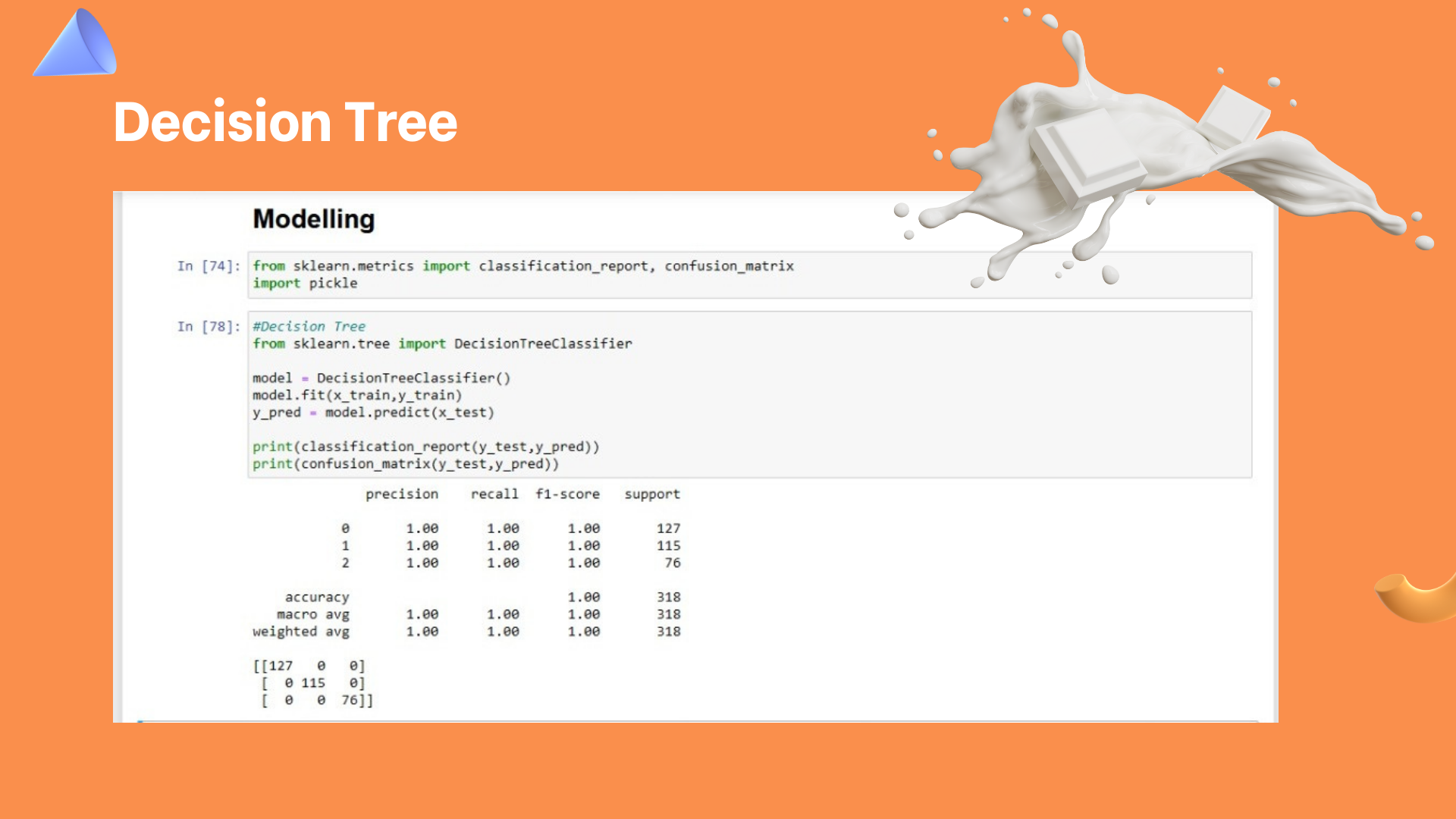
Decision Tree

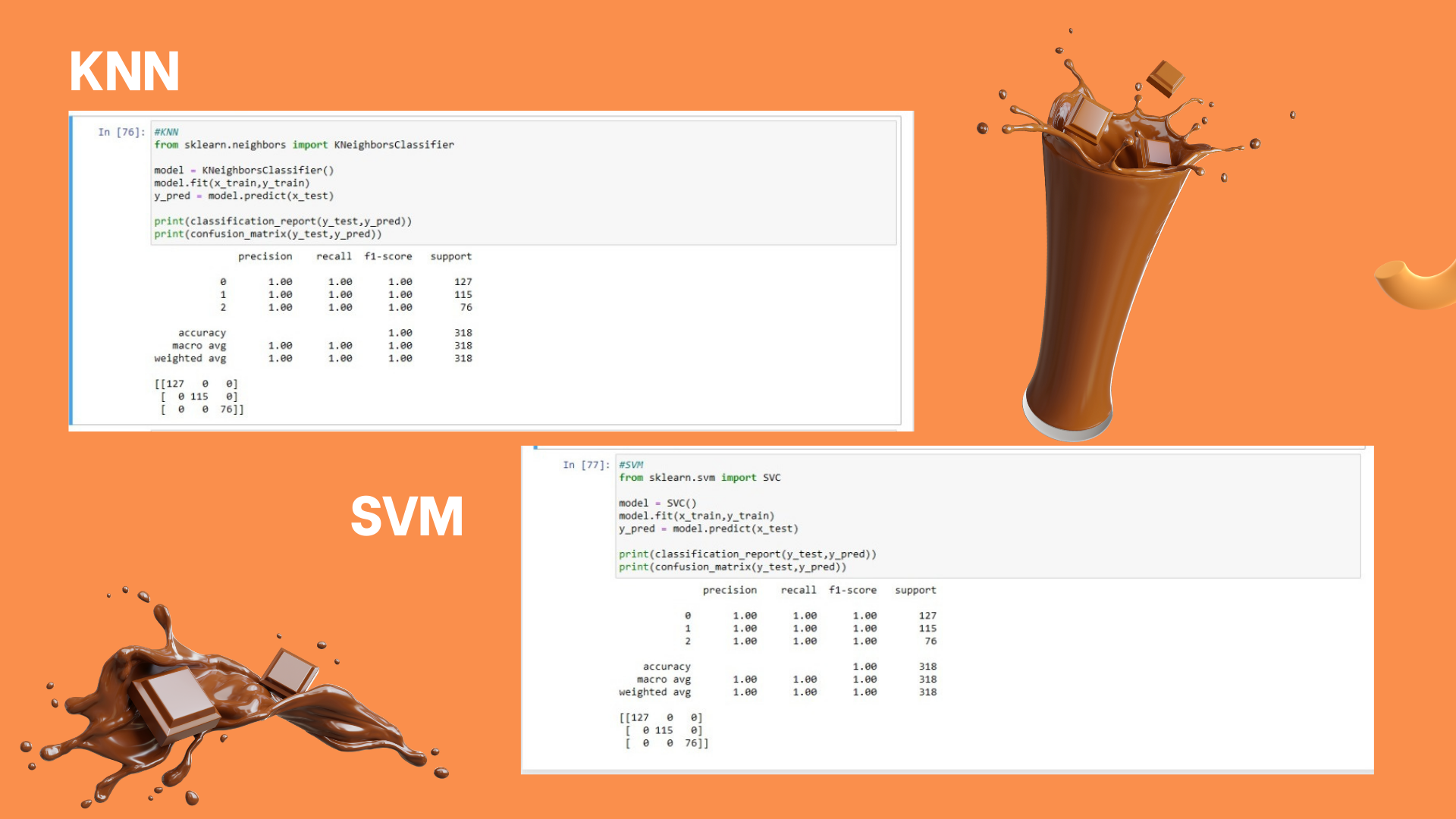
KNN

Support Vectore Machine (SVM)

Kesimpulan yang di dapat yaitu akurasi dari Milk quality menggunakan algoritma Decision Tree, KNN dan SVM yaitu 100%. Dengan demikian menggunakan algoritma machine learning dapat memudahkan dalam memperoleh suatu data yang dibutuhkan.
Informasi Course Terkait
Kategori: Artificial IntelligenceCourse: Machine Learning For Beginner

