
Klasifikasi Data IRIS dengan Model Decision Tree
Sulistiani Basyiah



Summary
Summary
Klasifikasi data adalah proses pengelompokkan data berdasarkan beberapa aspek di antaranya berdasarkan sumber data, cara memperolehnya, waktu pengumpulan, jenis, dan sifat data. Dataset pada pengujian ini diperoleh melalui Kaggle.com dan di olah menggunakan tools python. Dataset ini terdiri dari 3 spesies iris (Iris Setosa, Iris virginica, dan Iris versicolor) dan tiap spesies memiliki 50 sampel. Empat fitur yang diukur dari masing-masing sampel yaitu panjang dan lebar sepal dan kelopak, dalam sentimeter (Petal Length, Petal Width, Sepal Length, Sepal Width).
Description

Decision Tree
Decision tree merupakan suatu struktur yang digunakan untuk membantu proses pengambilan keputusan. Disebut sebagai “tree” karena struktur ini menyerupai sebuah pohon lengkap dengan akar, batang, dan percabangannya. Dalam data science, struktur decision tree dapat membantu ambil keputusan efektif dan tetap memperhatikan kemungkinan hasil serta konsekuensinya. Decision tree ini termasuk dalam Supervised Machine Learning Model dimana data terus-menurus dibagi menurut parameter tertentu dan akhirnya keputusan dibuat. Sebuah pohon decision tree biasanya berisi 3 jenis node.
Decision tree dapat digunakan dalam masalah regresi dan klasifikasi, dan disini akan dibahasa bagaimana proses decision tree diimplementasikan. Pohon klasifikasi ini akan digunakan untuk mengklasifikasikan variabel diskrit. misalnya mengklasifikasikan apakah sebuah rumah termasuk tipe 36 atau bukan.

Dataset
Klasifikasi data menggunakan decision tree dengan sumber data dari kaggle.com serta diolah menggunakan python dan google colaboratory. Data yang berhasil didownload adalah data IRIS, dataset ini terdiri dari 3 spesies iris (Iris Setosa, Iris virginica, dan Iris versicolor) dan tiap spesies memiliki 50 sampel. Empat fitur yang diukur dari masing-masing sampel yaitu panjang dan lebar sepal dan kelopak, dalam sentimeter (Petal Length, Petal Width, Sepal Length, Sepal Width).

Bagaimana Implementasi Praktiknya dalam Mengklasifikasi Dataset IRIS?
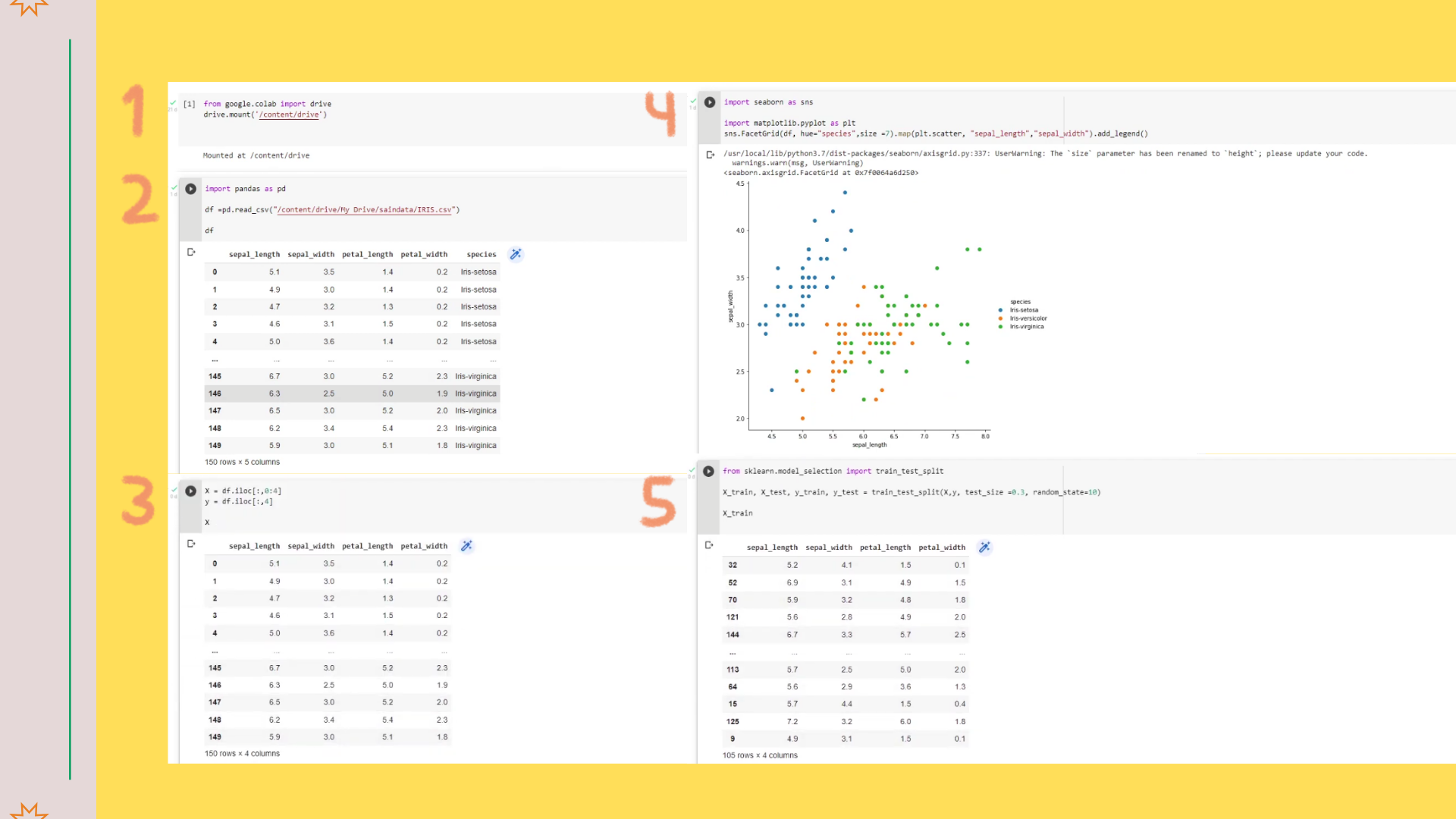
1. DOWNLOAD DATA bersumber dari: Kaggel.com
2. Buka google colab, dan tuliskan perintah untuk koneksikan ke google drive untuk dapat memasukkan data yang akan diklasifikasi > eksekusi/run

3. Tambahkan kode > masukkan data dan harus diletakkan di bagian file agar dapat ditarik lewat instruksi dibawah ini. Jika tidak akan muncul pesan error dimana data ‘IRIS.csv’ tidak ada.

4. Tambahkan instruksi dalam bentuk scatter plot, hal ini khusus data yang kurang dari 3 dimens jika lebih maka cukup instruksi yang diatas saja.

5. Klasifikasi dengan proses prediksi dengan mencoba bagi dua data tersebut dengan data parameter (x) dan data target (y) kemudian cek simpang data.

6. Coba tampilkan specius y atau targetnya.

7. Bagi dua menjadi data training dan data testing.

8. Terapkan model decision tree classification.

Kesimpulan: Berdasarkan perhitungan akurasinya penggunaan model decision tree berdasarkan data IRIS nilai akurasinya sebesar 97% dengan menerka apakah data-data itu berdasarakan sepal_length, sepal_width, petal_length, dan petal_width bisa memprediksi spesies mana, apakah masuk pada spesies iris-setosa, iris-versicolor, atau iris-virginica.
Informasi Course Terkait
Kategori: Artificial IntelligenceCourse: Machine Learning For Beginner



