
CNN untuk Klasifikasi Citra Bunga
Yisti Vita Via


Summary
Pada studi penelitian ini, algoritma Convolution Neural Network (CNN) diterapkan untuk klasifikasi jenis bunga yaitu Daisy, Sun Flower, Tulip, Dandelion, dan Rose. Dataset diunduh dari situs www.kaggle.com. Dari keseluruhan dataset hanya digunakan 100 citra yang mana masing-masing sebanyak 20 citra untuk setiap kelas bunganya. Dataset ini kemudian dibagi menjadi data latih dan data uji dengan proporsi yang seimbang pada setiap kelasnya yaitu 80 dibanding 20. Sebelum melalui tahap pelatihan, citra dilakukan resize sebesar 150x150 pixel. Model arsitektur CNN menggunakan Convolution 2D, Max Pooling 2D, Flatten, dan Dense, sedangkan tahap pelatihan menggunakan epoch 20 dan learning rate 0,001. Hasil akurasi menunjukkan perolehan sebesar 80%, sehingga pada studi berikutnya bisa dimodifikasi arsitektur CNN dan penambahan dataset citra untuk tahap pelatihan agar nilai akurasi bisa meningkat lebih baik lagi.
Description
SUMBER DAN UKURAN DATA
Dataset diunduh dari situs www.kaggle.com. Dari keseluruhan dataset hanya diambil 100 citra yang mana masing-masing sebanyak 20 citra untuk setiap kelas bunganya. Dataset ini kemudian dibagi menjadi data latih dan data uji dengan proporsi yang seimbang pada setiap kelasnya yaitu 80 dibanding 20. Dataset disimpan dalam Google Drive dan diakses sebagaimana terlihat pada instruksi program Gambar 1. Sedangkan contoh tampilan citra yang mewakili setiap kelasnya bisa dilihat pada Gambar 2.

Gambar 1. Tampilan Kode untuk Mengakses Dataset dari Google Drive

Gambar 2. Contoh Tampilan Citra Setiap Kelasnya
METODE PRAPROSES DATA
Sebelum dataset diproses dan diklasifikasikan dengan algoritma CNN, perlu dilakukan praproses data yaitu dengan mengubah citra menjadi ukuran 150x150 pixel. Selain itu citra juga dibaca dengan fungsi IMREAD_COLOR sebagaimana tampak pada instruksi program Gambar 3.

Gambar 3. Instruksi Program untuk Praproses Dataset
Selanjutnya dataset akan dilakukan pelabelan untuk kebutuhan output model, input model, dan normalisasi sebagaimana tampak pada Gambar 4, serta dilakukan split data untuk membagi dataset menjadi data latih dan data uji. Pada Gambar 5 bisa dilihat bahwa parameter untuk data uji adalah 0,2, sehingga sisanya adalah untuk data latih sebesar 0,8. Dengan demikian proporsi data latih dibanding data uji adalah 80 : 20.

Gambar 4. Tampilan Kode Program untuk Pelabelan Output Model, Input Model, dan Normalisasi Data

Gambar 5. Instruksi Program untuk Split data Latih dan Uji
TAHAPAN PEMODELAN
Setelah praproses data selesai dilakukan artinya dataset telah siap untuk ditraining dan uji model menggunakan arsitektur CNN. Pada Gambar 6 adalah tampilan instruksi program untuk membangun arsitektur CNN. Model arsitektur CNN menggunakan Convolution 2D, Max Pooling 2D, Flatten, dan Dense. Sedangkan Gambar 7 adalah tampilan hasil kesimpulan gambaran dari arsitektur CNN.

Gambar 6. Instruksi Kode Program Pemodelan CNN

Gambar 7. Tampilan Output Gambaran Model Arsitektur CNN
HASIL PEMODELAN
Hasil pemodelan dari arsitektur CNN merupakan hasil dari proses pelatihan dan pengujian menggunakan dataset. Tahap pelatihan menggunakan epoch 20 dan learning rate 0,001. Gambar 8 merupakan tampilan instruksi program untuk proses compile dan fitting model, diikuti dengan hasil tracing proses pelatihan hingga mendapatkan tingkat akurasi yang diinginkan. Sedangkan hasil evaluasi model bisa dilihat pada Gambar 9. Hasil akurasi menunjukkan perolehan sebesar 65%.

Gambar 8. Tampilan Program Compile dan Fitting Model

Gambar 9. Tampilan Program Evaluasi Model
ANALISA HASIL PEMODELAN
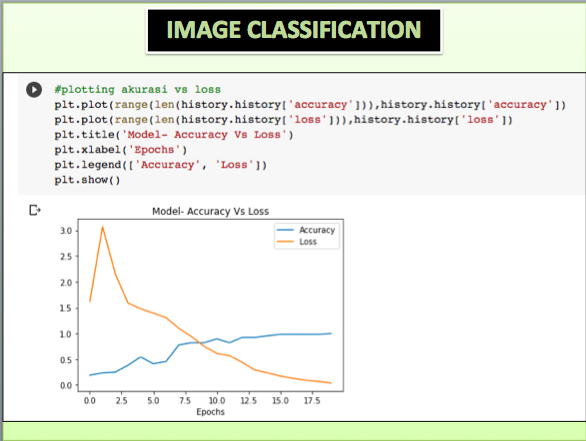
Berikutnya untuk menilai performansi model dilakukan plotting hasil akurasi terhadap nilai loss sebagaimana tampil pada Gambar 10. Pada studi berikutnya bisa dimodifikasi arsitektur CNN dan penambahan dataset citra untuk tahap pelatihan agar nilai akurasi bisa meningkat lebih baik lagi.

Gambar 10. Hasil Plotting Perbandingan Nilai Akurasi dan Loss
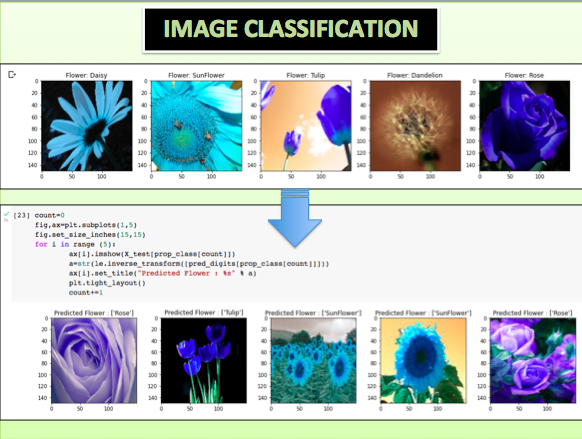
Untuk menampilkan contoh citra yang berhasil dan tidak berhasil diklasifikasi dengan benar, maka dilakukan penyimpanan dataset hasil klasifikasi ke dalam dua wariavel yaitu variabel prop_class dan mis_class. Hal ini ditunjukkan pada Gambar 11. Sedangkan tampilan contoh citra pada variabel prop_class yaitu citra yang berhasil diklasifikasi dengan benar ada di Gambar 12. Sebaliknya tampilan contoh citra pada variabel mis_class yaitu citra yang tidak berhasil diklasifikasi dengan benar ada di Gambar 13.

Gambar 11. Instruksi Program untuk Menyimpan Hasil Prediksi yang Sesuai dengan Target dan Tidak Sesuai Target

Gambar 12. Tampilan Penyajian Contoh Citra yang Berhasil Dideteksi dengan Benar

Gambar 13. Tampilan Penyajian Contoh Citra yang Tidak Berhasil Dideteksi dengan Benar
Informasi Course Terkait
Kategori: Data Science / Big DataCourse: Master Class On Job Training: Data Science Intensive Program Batch 33



