
MACHINE LEARNING FOR DIABETES PREDICTION
wahyu syaifullah jauharis saputra


Summary
Machine Learning Diabetes Prediction merupakan implementasi dari sebuah machine learning berbasis Neural Network untuk melakukan klasifikasi data pada dataset diabetes pima yang didapatkan dari kagle melalui tautan https://www.kaggle.com/datasets/uciml/pima-indians-diabetes-database. Dataset ini berasal dari National Institute of Diabetes and Digestive and Kidney Diseases. Tujuan dari kumpulan data adalah untuk memprediksi secara diagnostik apakah pasien menderita diabetes atau tidak, berdasarkan pengukuran diagnostik tertentu yang termasuk dalam kumpulan data. Beberapa kendala ditempatkan pada pemilihan contoh ini dari database yang lebih besar. Secara khusus, semua pasien di sini adalah perempuan berusia minimal 21 tahun dari keturunan Pima India.Dataset terdiri dari beberapa variabel prediktor medis dan satu variabel target, Hasil. Variabel prediktor meliputi jumlah kehamilan yang dialami pasien, BMI, kadar insulin, usia, dan sebagainya. Implementasi Machine Learning menggunakan bahasa pemrograman pyhton dengan langkah langkah sebagai berikut:
- Data Aquisition (load dataset pima indian diabetes dataset)
- Data Preparation
- Data Visualization (melihat korelasi fitur, serta melihat komposisi dari tiap fitur data)
- Data Scoring (membuat data kategorikal menjadi data numerikal)
- Data Normalization
- Feature Selection
- Mencari rata-rata korelasi fitur terhadap output
- Menyeleksi fitur yang memiliki korelasi diatas rata-rata
- Data Slicing (membagi data menjadi data Training dan Data Testing
- Model Design (menggunakan arsitektur Neural Network)
- Model Training
- Visualization of Accuracy
- Visualization of Data Loss
- Model Testing
- Model Evaluation
- Confusion Matrix Visualization
- Calculate Precision (tiap Klas dan rata-rata presisi)
- Calculate Recall (tiap klas dan rata-rata recall)
- Accuracy
Description
MACHINE LEARNING DIABETES PREDICTION
Wahyu S J Saputra
Dataset
Dataset yang digunakan dalam Tugas Akhir ini adalah Pima Indians Diabetes Database. Dataset ini berasal dari National Institute of Diabetes and Digestive and Kidney Diseases. Tujuan dari kumpulan data adalah untuk memprediksi secara diagnostik apakah pasien menderita diabetes atau tidak, berdasarkan pengukuran diagnostik tertentu yang termasuk dalam kumpulan data. Beberapa kendala ditempatkan pada pemilihan contoh ini dari database yang lebih besar. Secara khusus, semua pasien di sini adalah perempuan berusia minimal 21 tahun dari keturunan Pima India.
Dataset terdiri dari beberapa variabel prediktor medis dan satu variabel target, Hasil. Variabel prediktor meliputi jumlah kehamilan yang dialami pasien, BMI, kadar insulin, usia, dan sebagainya, dengan detail seperti berikut.
|
|
|
|
|
|
|
|








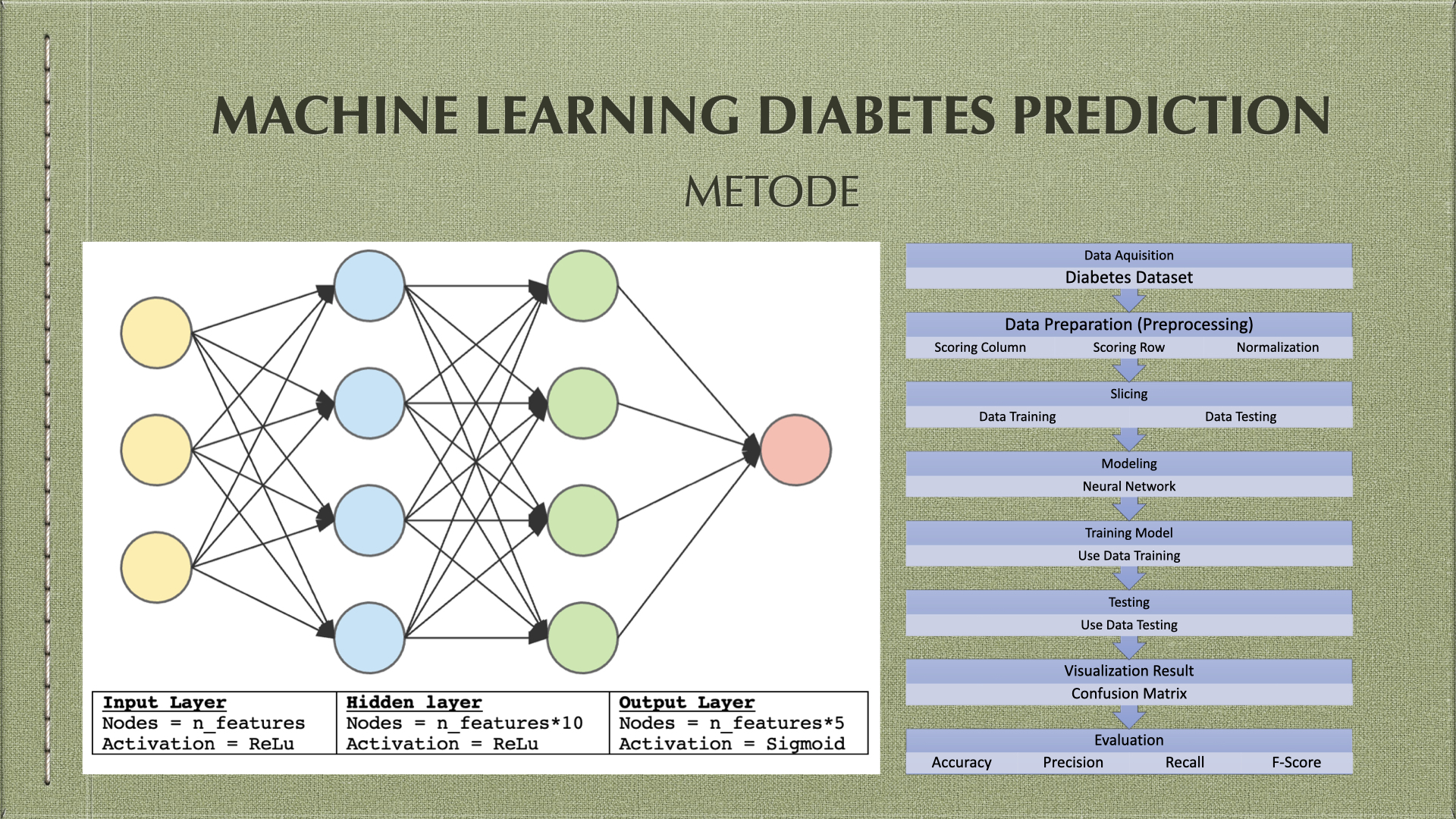
Metode

Model Machine Learning

Implementasi Dengan Menggunakan Python
Kode program diawali dengan import library yang dibutuhkan
Pandas untuk membaca dataset csv dalam bentuk dataframe, dan beberapa library pendukung tambahan.
import pandas as pd #membaca csv_file
# import tensorflow as tf
import numpy as np #operasi Array
import matplotlib #operasi Visualisasi Plot
import matplotlib.pyplot as plt
import seaborn as sns
import statsmodels.api as sm
from numpy import mean #menghitung mean dalam list
from tensorflow import keras
from keras.models import Sequential
from keras.layers import Dense
from sklearn.metrics import confusion_matrix, classification_report
from sklearn import metrics
from google.colab import drive
Data Acquisition
Pada bagian akuisisi data. Dataset yang telah disiapkan dalam google drive dengan alamat file 'gdrive/My Drive/Colab Notebooks/diabetes-updated-dataset.csv dibuka dengan menggunakan statement seperti berikut:
drive.mount('/content/gdrive')
data_frame = pd.read_csv('gdrive/My Drive/Colab Notebooks/diabetes-updated-dataset.csv')
features = list(data_frame.columns) #daftar fitur/kolom dataset
NUM_OF_FEATURE = len(features) #konstanta jumlah fitur/kolom dataset
Daftar fitur dan konstanta jumlah fitur merupakan variabel yang akan dipakai secara berulang pada proses berikutnya.
Berikutnya adalah proses analisis korelasi masing-masing fitur dan ditampilkan dalam heatmap menggunakan kode berikut.
plt.figure(figsize=(10 , 10))
sns.heatmap(data_frame.corr(), annot = True, cmap = plt.cm.Greys)
plt.show()
kode tersebut menghasilkan output seperti pada gambar dibawah ini

Dari visualisasi tersebut didapatkan kesimpulan bahwa nilai korelasi dari setiap fitur pada dataset yang digunakan paling tinggi adalah antara ‘Age’ dan ‘Pregnancies’ yaitu sebesar 0,54. Korelasi fitur tertinggi terhadap ‘outcome’ atau target adalah fitur ‘glucose’ dimana memiliki nilai korelasi 0,47.
Data Preparation (Preprocessing)
Scoring column
Pada dataset masih ditemukan adanya missing value yaitu data yang memiliki fitur dengan nilai 0 (nol), maka pada kode berikut dilakukan perhitungan presentase data dengan missing value pada masing-masing fitur.
columnScore = {}
for i in range(0, NUM_OF_FEATURE - 1):
columnScore[features[i]] = len(data_frame[data_frame[features[i]] == 0].index)/data_frame[features[i]].shape[0]
columnScore
didapatkan nilai missing value pada masing-masing fitur adalah sebagai berikut.
'Pregnancies': 0.14453125,
'Glucose': 0.006510416666666667,
'BloodPressure': 0.045572916666666664,
'SkinThickness': 0.2955729166666667,
'Insulin': 0.4869791666666667,
'BMI': 0.014322916666666666,
'DiabetesPedigreeFunction': 0.0,
'Age': 0.0
Terlihat bahwa pada fitur ‘insulin’ didapatkan nilai missing value paling tinggi sedangkan fitur ‘Age’ dan ‘DiabetesPredigreeFunction’ tidak ditemukan adanya missing value. Tahap berikutnya adalah menyeleksi fitur dilakukan dengan membandingkan korelasi fitur terhadap target dan nilai persentase missing value seperti pada kode berikut.
target_dep = {}
for i in range(0, NUM_OF_FEATURE - 1):
target_dep[features[i]] = data_frame[features[NUM_OF_FEATURE - 1]].corr(data_frame[features[i]])
avg_target_dep = sum(target_dep.values()) / len(target_dep)
# removing feature with percentage of missing values > 20%
for i in range(0, NUM_OF_FEATURE - 1):
if(columnScore[features[i]] > 0.2 and target_dep[features[i]]):
data_frame.drop(features[i], inplace=True, axis=1)
sehingga didapatkan daftar fitur baru sebagai berikut
# New Features
features = list(data_frame.columns )
NUM_OF_FEATURE = len(features)
features
kode tersebut menghasilkan output daftar fitur yang terseleksi dan juga kolom target seperti pada daftar fitur berikut.
'Pregnancies',
'Glucose',
'BloodPressure',
'BMI',
'DiabetesPedigreeFunction',
'Age',
'Outcome'
Scoring Row
Tahap berikutnya adalah menyeleksi baris data yang memiliki missing value menggunakan kode program berikut.
# check data with missing values
listIndex = []
for i in range(0, NUM_OF_FEATURE - 1):
listIndex.append(list(data_frame[data_frame[features[i]] == 0].index))
rowsHaveMissingValues = set(listIndex[0])
data_frame = data_frame.drop(rowsHaveMissingValues)
Hasil akhir dari tahap ini adalah didapatkan dataset dalam bentuk dataframe yang didalamnya sudah tidak ditemukan lagi missing value (clean data)
Normalisasi
Kode normalisasi adalah sebagai berikut.
data_frame_norm = (data_frame - data_frame.min())/(data_frame.max() - data_frame.min())
kode tersebut mengubah data semula memiliki range 0 – n menjadi 0 – 1 sehingga value pada setiap data menjadi tipe ‘float’. Perubahan data sebelum dan sesudah dapat dilihat pada tabel berikut.
Sebelum Normalisasi | Sesudah Normalisasi |
|
|


Slicing Data
Pada tahap ini data dibagi menjadi data positif dan data negatif, selanjutya pada setiap klas (positif dan negatif) dilakukan pemilihan data secara acak dengan komposisi 80% sebagai data training dan 20% sebagai data testing. Terdapat 2 data_frame yang diproses yaitu data_frame dengan nilai biasa dan data_frame dengan nilai yang telah dilakukan normalisasi menggunakan kode berikut.
true_data_frame = data_frame[data_frame['Outcome']==1.0]
false_data_frame = data_frame[data_frame['Outcome']==0.0]
true_data_frame_norm = data_frame_norm[data_frame_norm['Outcome']==1.0]
false_data_frame_norm = data_frame_norm[data_frame_norm['Outcome']==0.0]
# Slice data per-class 80% (training): 20% (testing)
# Dataframe (raw)
true_train_data = true_data_frame.sample(frac = 0.8, random_state = 25)
true_test_data = true_data_frame.drop(true_train_data.index)
false_train_data = false_data_frame.sample(frac = 0.8, random_state = 25)
false_test_data = false_data_frame.drop(false_train_data.index)
train_data = pd.concat([true_train_data, false_train_data])
test_data = pd.concat([true_test_data, false_test_data])
# Dataframe (normalisasi)
true_train_data_norm = true_data_frame_norm.sample(frac = 0.8, random_state = 25)
true_test_data_norm = true_data_frame_norm.drop(true_train_data.index)
false_train_data_norm = false_data_frame_norm.sample(frac = 0.8, random_state = 25)
false_test_data_norm = false_data_frame_norm.drop(false_train_data.index)
train_data_norm = pd.concat([true_train_data_norm, false_train_data_norm])
test_data_norm = pd.concat([true_test_data_norm, false_test_data_norm])
sehingga didapat komposisi data
No. of training examples (80%) : 526
No. of testing examples (20%) : 131
Tahap berikutnya adalah memisahkan antar fitur dan target untuk proses training dan testing
X_train = train_data.to_numpy()[:, 0:(NUM_OF_FEATURE - 1)] #feature
y_train = train_data.to_numpy()[:,NUM_OF_FEATURE - 1] #target
X_test = test_data.to_numpy()[:, 0:(NUM_OF_FEATURE - 1)] #feature
y_test = test_data.to_numpy()[:, NUM_OF_FEATURE - 1] #target
X_train_norm = train_data_norm.to_numpy()[:, 0:(NUM_OF_FEATURE - 1)] #feature
y_train_norm = train_data_norm.to_numpy()[:,NUM_OF_FEATURE - 1] #target
X_test_norm = test_data_norm.to_numpy()[:, 0:(NUM_OF_FEATURE - 1)] #feature
y_test_norm = test_data_norm.to_numpy()[:, NUM_OF_FEATURE - 1] #target
Modeling
Tahap berikutnya adalah mempersiapkan model sesuai dengan arsitektur yang telah dibahas sebelumnya dengan spesifikasi sebagai berikut
Input Layer Nodes = n_features aktifasi = ReLu | Hidden layer 1 Nodes = n_features*10 aktifasi = ReLu | Hidden layer 2 Nodes = n_features*5 aktifasi = ReLu | output layer Nodes = n_target aktifasi = Sigmoid |
Fungsi aktifasi yang berbeda akan menghasilkan luaran yang berbeda sesuai dengan range output dari setiap fungsi aktifasi pada gambar berikut.

Fungsi sigmoid digunakan pada layer output karena target dari dataset bernilai 1 – 0 yaitu positif atau negatif. Kode program untuk membuat model adalah sebagai berikut.
model = Sequential()
model.add(Dense((NUM_OF_FEATURE - 1) * 10, input_dim = (NUM_OF_FEATURE - 1), activation = 'relu'))
model.add(Dense((NUM_OF_FEATURE - 1) * 5, activation = 'relu'))
model.add(Dense(1, activation = 'sigmoid'))
model.compile(loss = 'binary_crossentropy', optimizer = 'adam', metrics = ['accuracy'])
Training
proses training menggunakan parameter ‘epochs’ sebesar 400 dan ‘validation_data’ menggunakan data tes, sedangkan perbaikan bobot dilakukan setiap 10 data (‘batch_size’). Dengan menggunakan kode program berikut
history_norm = model_norm.fit(X_train, y_train, epochs=400, batch_size=10, verbose=0, validation_data=(X_test_norm, y_test_norm))
Visualisasi proses training dilakukang dengan menggunakan kode program berikut
# summarize history for accuracy
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.title('model accuracy')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper left')
plt.show()
# summarize history for loss
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper left')
plt.show()
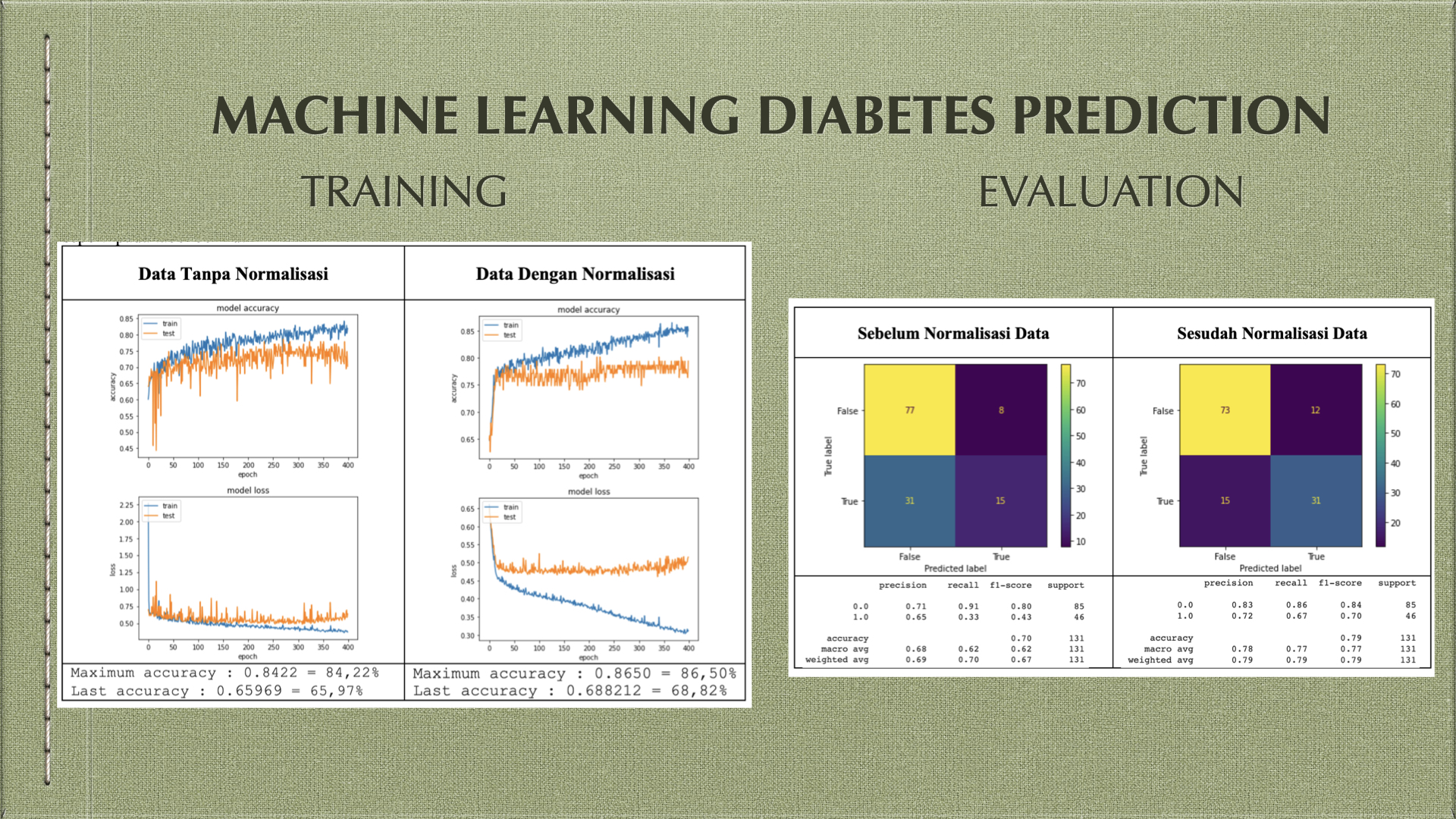
maka terlihat grafik nilai akurasi pada data sebelum normalisasi dan sesudah normalisasi seperti pada tabel berikut
Data Tanpa Normalisasi | Data Dengan Normalisasi |
|
|
Maximum accuracy : 0.8422 = 84,22% Last accuracy : 0.65969 = 65,97% | Maximum accuracy : 0.8650 = 86,50% Last accuracy : 0.688212 = 68,82% |


Testing
Tahap testing adalah tahap menguji model yang sudah dibangun dan dilatih, menggunakan data yang berbeda dengan data training, kode program berikut adalah statement untuk menguji
y_pred = model.predict(X_test)
y_pred = np.around(y_pred)
y_pred_norm = model_norm.predict(X_test_norm)
y_pred_norm = np.around(y_pred_norm)
karena output dari model adalah floating poin, maka perlu dibulatkan untuk mendapatkan output yang bernilai 0 dan 1 (negatif dan positif)
Evaluation
Tahap evaluasi adalah melihat confusion matriks menggunakan kode perogram berikut.
confusion_matrix = metrics.confusion_matrix(y_test, y_pred)
cm_display = metrics.ConfusionMatrixDisplay(confusion_matrix = confusion_matrix, display_labels = [False, True])
cm_display.plot()
plt.show()
print(classification_report(y_test, y_pred))
Hasil visualisasi dari evaluasi seperti terlihat pada tabel berikut
Sebelum Normalisasi Data | Sesudah Normalisasi Data |
|
|
|
|




Kesimpulan
Pada dataset diabetes setelah dilakukan eliminasi fitur dan data yang memiliki missing values kemudian dibangun model klasifikasi Nerual Network dengan spesifikasi yang telah dijelaskan sebelumnya maka didapatkan hasil sebagai berikut.
- Akurasi untuk data yang telah di normalisasi yaitu 79%, nilai ini lebih tinggi dibandingkan data tanpa normalisasi yang mendapatkan nilai akurasi 70%.
- Rata-rata tingkat presisi untuk data yang telah di normalisasi yaitu 78%, nilai ini lebih tinggi dibanding dengan data tanpa normalisasi yang mendapatkan rata-rata nilai presisi 68%.
- Rata-rata tingkat recall untuk data yang telah dinormalisasi yaitu 77% nilai ini lebih tinggi dibandingkan dengan data tanpa normalisasi yang mendapatkan rata-rata nilai recall 62%.
- Normalisasi pada data diabetes mampu meningkatkan akurasi sebesar 9%, rata-rata presisi sebesar 10%, dan rata-rata recal sebesar 15%.
Saran
- Jumlah data yang lebih banyak akan membantu model dalam proses training dan memungkinkan untuk dapat meningkatkan akurasi maupun presisi.
- Perbandingan jumlah data positif dan negatif yang seimbang diperlukan untuk melatih model
- Missing values perlu diperhatikan
Informasi Course Terkait
Kategori: Artificial IntelligenceCourse: Master Class On Job Training: Data Science Intensive Program Batch 33
