
Klasifikasi Data Kanker Paru-Paru
Henni Endah Wahanani
Summary
Untuk proyek data science ini, saya menerapkan model machine learning untuk menyelesaikan masalah klasifikasi kanker paru-paru. Dataset ini diambil dari kaggle memiliki 309 data dengan 13 kolom. Singkatnya, tujuan dari model machine learning ini adalah untuk memprediksi apakah seorang pasien menderita kanker paru-paru jika diberikan 12 fitur dan 1 target. Membagi data dengan 80% data training dan 20% data testing didapatkan hasil 247 data training, 62 data testing. Terdapat 2 model dalam pengujian terdiri dari 3 layer dense, layer dense pertama 12 node, kedua 8 node. Model 1 untuk data asli menghasilkan akurasi 87%. Sedangkan model 2 untuk data yang sudah terseleksi menghasilkan akurasi 90%.
Description
Pendahuluan
Efektivitas sistem prediksi kanker membantu masyarakat untuk mengetahui risiko kanker mereka dengan biaya rendah dan juga membantu masyarakat untuk mengambil keputusan yang tepat berdasarkan status risiko kanker mereka. Data dikumpulkan dari website online sistem prediksi kanker paru-paru. Dataset diambil dari : https://www.kaggle.com/datasets/mysarahmadbhat/lung-cancer
Rincian ke-12 fitur tersebut adalah sebagai berikut:
- GENDER
- AGE
- SMOKING
- YELLOW_FINGERS
- ANXIETY
- PEER_PRESSURE
- CHRONIC DISEASE
- FATIGUE
- WHEEZING
- ALCOHOL CONSUMING
- SHORTNESS OF BREATH
- CHEST PAIN
1 target : LUNG_CANCER
- Connect ke google colab

2. Load Dataset
pertama memuat dataset sebagai kerangka data pandas


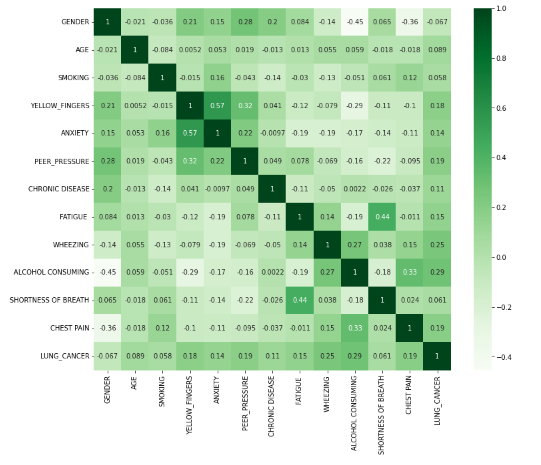
3. Nilai Korelasi

Hasil print :
Nilai korelasi
[-0.06725417467830659, 0.08946457606623369, 0.05817888585203872, 0.18133896271065755, 0.14494713288731198, 0.1863876317154079, 0.11089109464241381, 0.15067295875611647, 0.2492999598990599, 0.28853280309173096, 0.06073844947572164, 0.1904506951100535]
Rata-rata korelasi
0.1369707479607033
4. Menghapus fitur yang memiliki korelasi < rata2 korelasi

5. Membagi data training 80% data testing 20%

6. Menampilkan jumlah record data training dan data testing

Hasil print :
data train: 247
testing data: 62
data train: 247
testing data: 62
7. x adalah kolom2 fitur yang akan dibandingkan dengan target (y)

8. MODEL1 untuk data asli terdiri dari 3 layer dense,layer dense pertama 12 node, kedua 8 node, ketiga 1 node

Hasil print :

9. Training model 1

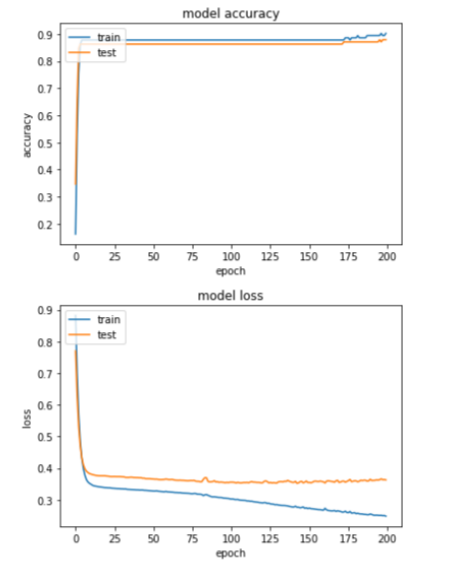
10. Menampilkan akurasi dan loss training model 1

Hasil akurasi dan loss training :

11. Menampilkan akurasi tertinggi dan akurasi terakhir dari proses model training 1

Hasil print :

12. Proses testing

13. Menampilkan confusion matrik dari data testing

Hasil print :

14. MODEL2 untuk data yang sudah terseleksi terdiri dari 3 layer dense,layer dense pertama 12 node, kedua 8 node, ketiga 1 node

Hasil print :


15. Menampilkan akurasi tertinggi dan akurasi terakhir dari proses model training 2

Hasil print :

16. Menampilkan confusion matrik dari data testing

Hasil print :

Informasi Course Terkait
Kategori: Data Science / Big DataCourse: Master Class On Job Training: Data Science Intensive Program Batch 33



