
Diamond Price Prediction Using Linear Regression
Fetty Tri Anggraeny


Summary
Dalam penelitian ini akan dilakukan prediksi harga berlian menggunakan dataset dari Kaggle Diamond Price 2022. Variabel Price merupakan data kontinyu, maka dalam penelitian ini menggunakan teknik regresi dengan metode Regresi Linier. Dalam penelitian ini digunakan 3 skenario yaitu:
- Menggunakan seluruh fitur dataset
- Menggunakan fitur dengan nilai korelasi < 0,25
- Menggunakan fitur turunan (size) yang dihitung menggunakan 3 variabel asli: x*y*z
Berdasarkan 3 skenario ujicoba yang telah dilakukan, ketiga scenario memberikan hasil yang baik dan dapat digunakan sebagai dasar prediksi dengan nilai R2 score > 80%. Ujicoba juga menunjukkan bahwa proses seleksi fitur berdasarkan nilai korelasi tidak memberikan dampak signifikan pada performa regresi. Hal ini tampak pada scenario 2 dan scenario 3 yang memiliki nilai R2 score, RMS dan MAE sedikit di bawah performa scenario 1.
Description
A. Tujuan penelitian/pengolahan data
Dalam penelitian ini akan dilakukan prediksi harga berlian menggunakan dataset dari Kaggle Diamond Price 2022. Variabel Price merupakan data kontinyu, maka dalam penelitian ini menggunakan teknik regresi dengan metode Regresi Linier. Dalam penelitian ini digunakan 3 skenario yaitu:
- Menggunakan seluruh fitur dataset
- Menggunakan fitur dengan nilai korelasi < 0,25
- Menggunakan fitur turunan (size) yang dihitung menggunakan 3 variabel asli: x*y*z
B. Dataset
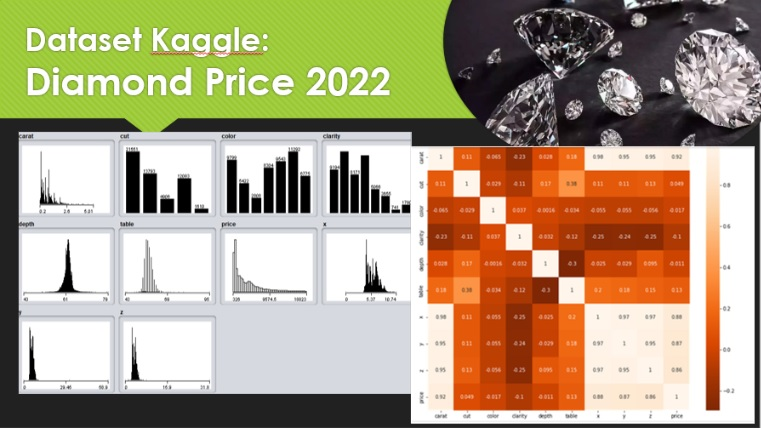
Dataset Diamond Price 2022 diperoleh dari website Kaggle https://www.kaggle.com/datasets/nancyalaswad90/diamonds-prices, dengan total data 53943 record, 10 variabel. Variabel feature ‘carat’, ‘cut’, ‘color’, ‘clarity’, ‘depth’, ‘table’, ‘x’, ‘y’, and ‘z’, dan variable target ‘price’.

Karakteristik setiap variabel data dapat dilihat dari aplikasi Weka sebagai berikut:

Kode 1. Mempersiapkan data frame untuk menampung dataset:

Kode 2. Mengekstrak beberapa Informasi dari dataset, antara lain nama variabel, jumlah variabel, tipe data setiap variable dan ukuran dataset:

Kode 3. Menampilkan dataset

C. Metode/cara penyiapan dan pembersihan data
Berdasarkan karakteristik data dari aplikasi Weka tidak ditemukan missing value, sehingga tidak ada diperlukan penanganan lebih lanjut. Terdapat 3 variabel yang kategorikal non-numerik, maka dilakukan pengubahan menjadi numerik. Selain itu dilakukan seleksi fitur, untuk fitur dengan nilai korelasi absolut < 0,25 tidak digunakan dalam proses prediksi.
Kode 4. Variabel ‘cut’, ‘color’ dan ‘clarity’ merupakan data kategorikal non numerik, maka diubah menjadi numerik. Dengan bantuan aplikasi Weka untuk mengetahui varian value dari setiap variable:

Tampak bahwa
Variabel ‘cut’ memiliki 5 nilai: ‘Ideal’, ‘Premium’, ‘Good’, ‘Very Good’, dan ‘Fair’
Variabel ‘color’ memiliki 7 nilai: ‘E’, ‘I’, ‘J’, ‘H’, ‘F’, ‘G’, dan ‘D’
Variabel ‘clarity’ memiliki 8 nilai: ‘SI1’, ‘SI2’, ‘VS1’, ‘VS2’, ‘VVS1’, ‘VVS2’, ‘I1’, dan ‘IF’
Ketiga variable tersebut tidak memiliki missing value, karena apabila ditotal jumlah record setiap variable sama dengan 53943, sesuai dengan jumlah baris data dataset.
Berdasarkan Informasi dari Weka, maka dibuat pengkodean di phyton menggunakan fungsi replace() seperti pada capture berikut:

Setelah dilakukan pengkodean, maka dataset menjadi sebagai berikut (bandingkan dengan original dataset pada langkah 3):

Kode 5. Untuk memudahkan proses berikutnya, maka dilakukan penataan urutan variable. Variabel target ‘Price’ diletakkan di kolom terakhir dataset:

Kode 6. Menampilkan grafik korelasi antar variabel

Perhatikan kolom/baris terakhir, korelasi antara variable feature dengan variable target. Variable dengan nilai absolut korelasi tertinggi adalah ‘carat’, dilanjutkan dengan ‘y’, ‘z’, ’x’, ’cut’, ’color’, ’table’, ’depth’, dan ‘clarity’.
Kode 7. Apabila kita tampilkan dalam bentuk scatter plot maka tampak jelas hubungan linier antar variabel


D. Model yang digunakan dan tahapan-tahapannya
Model yang digunakan adalah Regresi Linier diterapkan dalam 3 skenario perbedaan variable data yang digunakan sebagai fitur.
SKENARIO 1: MENGGUNAKAN SELURUH FITUR DATASET
Kode 8. Persiapan data train dan data test dengan menggunakan proporsi 80%

Kode 9. Linier Regresi

SKENARIO 2: MENGGUNAKAN FITUR DENGAN NILAI KORELASI < 0,25
Berdasarkan analisa korelasi, ada beberapa fitur yang memiliki nilai korelasi rendah. Dalam proses berikutnya, variable yang memiliki nilai korelasi rendah dihapus dari dataset. Sehingga fitur yang dipertahankan adalah ‘carat’, ‘x’, ‘y’, ‘z’, ‘price’.
Kode 10. Penghapusan fitur dengan nilai korelasi < 0,25 dan pembagian data train dan test

Kode 11. Proses Train, Test, dan evaluasi dari selected feature

SKENARIO 3: MENGGUNAKAN FITUR TURUNAN (SIZE) YANG DIHITUNG MENGGUNAKAN 3 VARIABEL
ASLI: X*Y*Z
Kode 12. Menambahkan variable turunan ‘size’

Kode 13. Pembagian data train dan data test

Kode 14. Proses Train, test, dan evaluasi

E. Hasil pemodelan
SKENARIO 1

SKENARIO 2

SKENARIO 3

F. Analisa Hasil Pemodelan
Berdasarkan 3 skenario ujicoba diatas, ketiga scenario memberikan hasil yang baik dan dapat digunakan sebagai dasar prediksi dengan nilai R2 score > 80%. Ujicoba juga menunjukkan bahwa proses seleksi fitur berdasarkan nilai korelasi tidak memberikan dampak signifikan pada performa regresi. Hal ini tampak pada scenario 2 dan scenario 3 yang memiliki nilai R2 score, RMS dan MAE sedikit di bawah performa scenario 1.
Informasi Course Terkait
Kategori: Data Science / Big DataCourse: Master Class On Job Training: Data Science Intensive Program Batch 33
