
Portofolio Job Classification
Made Hanindia Prami Swari



Summary
Dataset pada portofolio ini diunduh dari : https://www.kaggle.com/datasets/HRAnalyticRepository/job-classification-dataset. Klasifikasi yang dilakukan adalah untuk menentukan paygrade dari masing-masing karyawan berdasarkan fitur-fitur yang dimiliki, seperti posisi jabatan, pengalaman kerja, dan sebagaianya. Adapun klasifikasi dilakukan menggunakan 2 model macine learning yakni Logostic Regression dan Decission Tree dengan langkah-langkah pengerjaan sebagai berikut :
1. Load data
2. Preprocessing Data : Menghilangkan fitur bernilai null dan Memberi label fitur bertipe object menjadi integer
3. Membuat model Logistic Regression
4. Membuat Model Decission Tree
5. Proses Training
6. Proses testing
7. Evaluasi
Description
Klasifikasi dengan Logistic Regression dan Decission Tree pada Kasus Job Classification
Import Library

Untuk dapat memanggil fungsi-fungsi yang akan digunakan pada Phyton, maka perlu dilakukan import library terlebih dahulu
Mount Drive

Dataset yang akan digunakan untuk prose klasifikasi diletakkan pada Drive, sehingga untuk dapat mengakses drive tersebut dibutuhkan proses untuk mount drive.
Membaca dan Menampilkan Dataset

Untuk mendefinisikan dataset yang akan diklasifikasikan maka digunakan script pd.read__csv. Sedangkan untuk menampilkan dataset yang akan diklasifikasikan, maka digunakan script db.info()
Menampilkan 3 Data Teratas

Untuk melihat Data yang terdapat pada Dataset maka digunakan script df.head
Preprocessing 1 : Menampilkan Nilai Null

Untuk dapat dihitung dalam model yang dibangun, maka harus dilakukan cleansing untuk memastikan tidak ada nilai null dalam dataset yang digunakan. Untuk mengecek ada tidaknya ilai null maka digunakan fungsi df.isnull()
Menampilkan Data Bertipe Object

Selain data null, maka data yang tidak dapat dihitung dalam model adalah data bertipe text (object), untuk itu harus dilakukan preprocessing pada data-data yang bertipe object. Untuk menemukan data bertipe object dapat digunakan fungsi df.select_datatypes(“object”).columns
Preprocessing 2 : Merubah serta Mengisi Nilai pada Data Bertipe Object

Untuk dapat diproses dalam model yang dibangun, maka data-data bertipe object harus dirubah menjadi integer dan diberi nilai. Untuk itu maka digunakan fungsi preprocessing.LabelEncoder dan untuk mengisi seluruh data maka harus dilakukan perulangan untuk seluruh data yag harus diisi menggunakan fungsi le.fit_transform.
Menampilkan Data yang Telah Dilabelling

Untuk memastikan bahwa data telah bertipe integer, maka perlu ditampilkan data pada dataset
Menentukan Variabel Dependent dan Independent

Untuk dapat melakukan klasifikasi, maka fitur-fitur yang terdapat pada dataset dimasukkan pada sebuah variabel (X) untuk fitur-fitur dependent, sedangkan variabel independent dimasukkan dalam variabel y
Menentukan Jumlah Data Training dan Test

Untuk melakukan evaluasi model yang dibangun, maka perlu ditentukan jumlah data training dan data test. Pada model yang dibangun digunakan jumlah data training adalah sebesar 70% dan data testing sebesar 30% dari total keseluruhan data
Model 1 : Logistic Regression

Python menyediakan fungsi untuk melakukan Logistic Regression pada dataset yang dimiliki. Untuk menggunakan fungsi ini dapat dilakukan dengan script LogisticRegression()
Evaluasi Model Logistic Regression

Untuk melakukan evaluasi terhadap Model Logistic Regression yang telah dibuat, maka dilakukan dengan menggunakan accuracy, recall, precission, f1 score
Model 2 : Decission Tree

Model kedua yang diguakan untuk melakuan klasifikasi adalah menggunakan Decission Tree. Adapun fungsi yang digunakan adalah dengan script DecissionTreeClassifier()
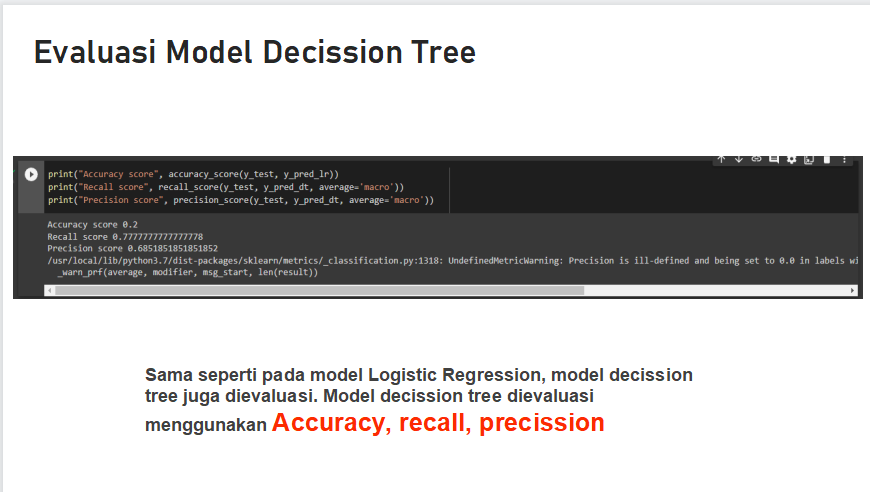
Evaluasi Model Decission Tree

Sama seperti pada model Logistic Regression, model decission tree juga dievaluasi. Model decission tree dievaluasi menggunakan Accuracy, recall, precission
Informasi Course Terkait
Kategori: Data Science / Big DataCourse: Master Class On Job Training: Data Science Intensive Program Batch 33
