
Indian Pima Diabetes Classification
Eva Yulia Puspaningrum



Summary
Klasifikasi suatu proses dalam mencari dan menentukan model atau fungsi yang dapat menjelaskan serta membedakan kelas data dengan tujuan dapat menggunakan data tersebut untuk memperkirakan kelas suatu objek yang statusnya tidak diketahui. Dataset yang digunakan berasal dari National Institute of Diabetes and Digestive and Kidney Diseases. Dapat diambil di Kaggle dengan link: https://www.kaggle.com/datasets/uciml/pima-indians-diabetes-database. Tujuannya adalah untuk memprediksi secara diagnostik apakah pasien menderita diabetes atau tidak. Dataset terdiri dari beberapa variabel prediktor medis dan satu variabel target, Hasil. Variabel prediktor meliputi pregnancies, Glucose, BloodPressure, SkinThickness, Insulin, BMI, DiabetesPedigreeFunction, age, Outcome. Dimana outcome merupakan target dari data tersebut.
Description
Implementasi Klasifikasi Data Diabetes Indian Pima:
- Import Library yang akan diguanakan

- LOAD DATA -- Diabetes Indian Pima yang disimpan di variable data_frame

- Melihat Nama Atribut yang ada pada Datasetnya

- Melihat Korelasi antar atribut

- Hasil Korelasi -→ setelahnya akan dilakukan feature selection

- FEATURE SELECTION-- Menghapus korelasi dibawah 0,2 yaitu pada atribut BloodPressure, SkinThickness, Insulin, DiabetesPedigreeFunction

- Hasil dari dataset yang telah melakukan Feature Selection

- Split Data. Data dibagi menjadi data training dan data testing. Dimana data trainng adalah 80% dari jumlah data

- Data dibadi menjadi 2 tipe: 1) Data asli dari database (tanpa proses features selection) yang disimpan di variable x dan y . 2) data yang sudah dilakukan feature selection disimpan pada variable x_select dan y_select

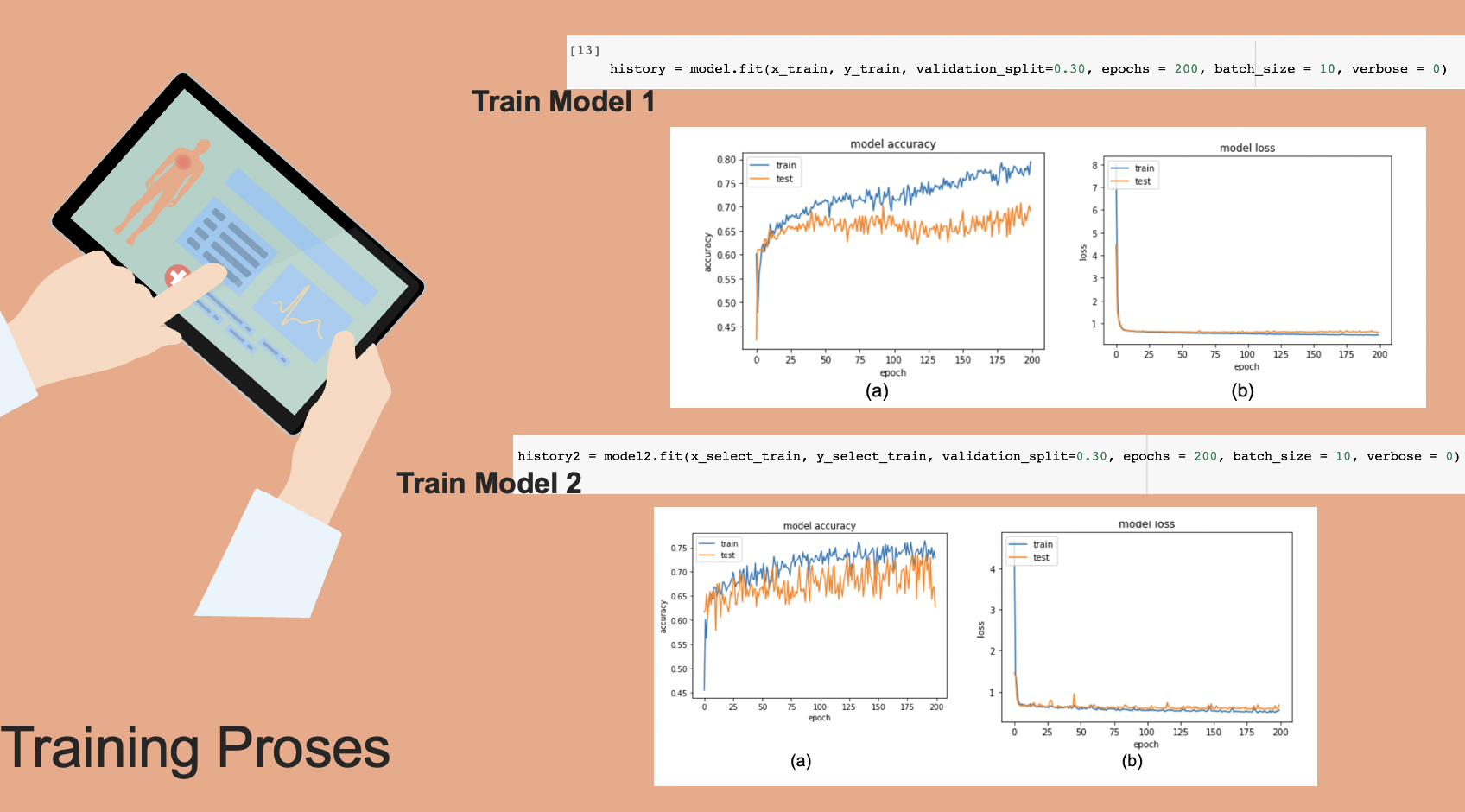
- MODEL 1-- Setelah itu akan dibuat model dengan pendekatan Machine Learning. Pada model 1, data yang diguankan adalah dataset asli yang belum dilakukan feature extraction

- Visualisasi hasil training Model 1

- MODEL 2 -- dibuat model dengan pendekatan Machine Learning, bedanya pada model 2 data yang diguankan adalah dataset yang sudah dilakukan feature extraction

- Visualisasi hasil training Model 2

- TESTING -- dilakukan testing data terhadap model 1 dan 2 yang telah dibanguan dengan menggunkan data uji yang telah disediakan yaitu 20% dari dataset.

- EVALUASI -- Model 1 memiliki akurasi sebesar 72%. Nilai Presisi 61% (TP/TP+FP) dan Recall 64% (TP/TP+FN) dan F-Measuer 63% ((2*Presisi*Recall)/(Presisi+Recall))

Model 2 memiliki akurasi sebesar 66%. Nilai Presisi 64% (TP/TP+FP) dan Recall 16% (TP/TP+FN) dan F-Measuer 26% ((2*Presisi*Recall)/(Presisi+Recall))

Informasi Course Terkait
Kategori: Data Science / Big DataCourse: Master Class On Job Training: Data Science Intensive Program Batch 33
