
Heart Attack Prediction in Indonesia Dataset
Fonda Leviany



Summary
Heart Attack Prediction in Indonesia Dataset menjadi rujukan untuk membantu mengidentifikasi individu berisiko tinggi sebelum serangan jantung terjadi. Penyakit jantung masih menjadi penyebab kematian nomor satu di seluruh dunia, dan paling sering menyerang kelompok usia produktif sehingga mortalitasnya berdampak pada peningkatan beban ekonomi sosial masyarakat. Dia juga mengatakan jika tingginya kasus kardiovaskuler di Indonesia disebabkan modified risk factor terkait gaya hidup yang tidak sehat (BRIN, 2024).Penyebab & Risiko (IDAI): Hipertensi, kolesterol tinggi, merokok, obesitas, kurang aktivitas fisik, dan stres. Dataset bersumber dari kaggle.com dengan data observasi sebanyak 158.355 dan 28 kolom. Dataset akan diolah dengan machine learning menggunakan metode Regresi Logistik, Decision Tree, Random Forest, dan Support Vector Machine.
Description
Heart Attack Prediction in Indonesia Dataset menjadi rujukan untuk membantu mengidentifikasi individu berisiko tinggi sebelum serangan jantung terjadi. Penyakit jantung masih menjadi penyebab kematian nomor satu di seluruh dunia, dan paling sering menyerang kelompok usia produktif sehingga mortalitasnya berdampak pada peningkatan beban ekonomi sosial masyarakat. Dia juga mengatakan jika tingginya kasus kardiovaskuler di Indonesia disebabkan modified risk factor terkait gaya hidup yang tidak sehat (BRIN, 2024).Penyebab & Risiko (IDAI): Hipertensi, kolesterol tinggi, merokok, obesitas, kurang aktivitas fisik, dan stres. Dataset bersumber dari kaggle.com dengan data observasi sebanyak 158.355 dan 28 kolom. Dataset akan diolah dengan machine learning menggunakan metode Regresi Logistik, Decision Tree, Random Forest, dan Support Vector Machine. 
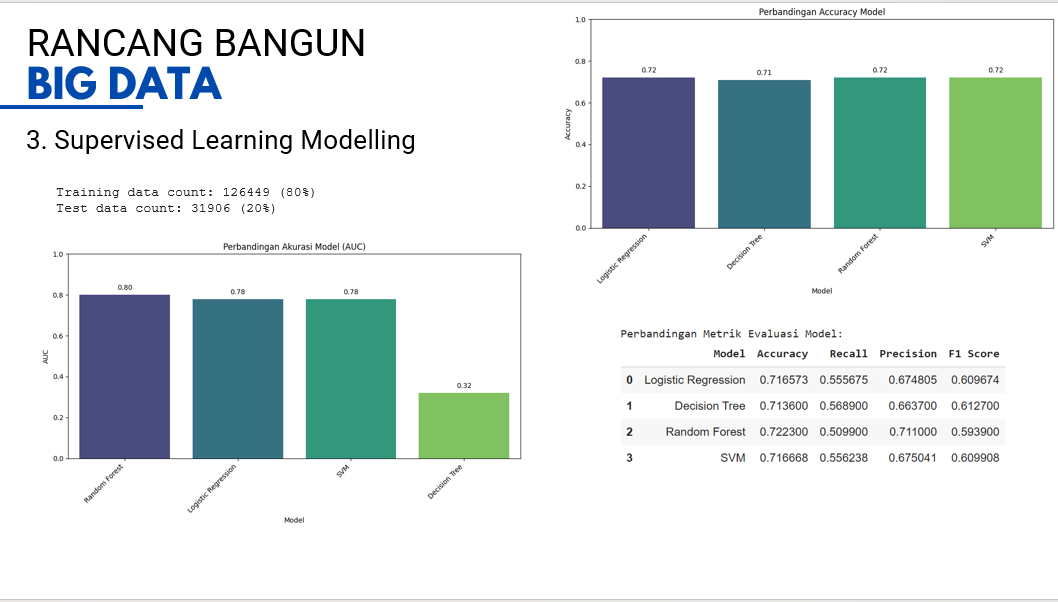
Berdasarkan hasil pengujian, nilai akurasi tertinggi diperoleh oleh tiga model, yaitu Logistic Regression, Random Forest, dan SVM, yang masing-masing mencapai 0,72. Sementara itu, Decision Tree memiliki akurasi sedikit lebih rendah, yaitu 0,71.
Secara umum, perbedaan akurasi antar model tergolong kecil, menunjukkan bahwa keempat model memiliki performa yang relatif seimbang dalam melakukan klasifikasi terhadap dataset yang digunakan. Namun, jika mempertimbangkan kestabilan dan kemampuan generalisasi, Random Forest dan SVM sering dianggap lebih unggul karena keduanya mampu menangani data yang kompleks dan mengurangi risiko overfitting dibandingkan Decision Tree tunggal.
Dengan demikian, model Random Forest atau SVM dapat dipertimbangkan sebagai pilihan terbaik untuk tahap analisis lanjutan atau penerapan dalam sistem prediksi, mengingat performa akurasi yang tinggi dan sifatnya yang lebih robust.
Informasi Course Terkait
Kategori: Data Science / Big DataCourse: Master Class Big Data dan Sertifikasi Nasional Big Data Scientist



