
Implementasi Metode TF-IDF dan Cosine Similarity
Indah Putriani Lahagu


Summary
MeloDetect dirancang untuk mengidentifikasi judul lagu dari potongan lirik yang diingat pengguna, baik melalui input ketikan teks maupun rekaman suara secara real time. Dengan memanfaatkan teknologi Natural Language Processing (NLP), aplikasi ini mengubah lirik menjadi vektor numerik menggunakan metode TF-IDF dan mengukur kemiripan dengan algoritma Cosine Similarity untuk menemukan lagu yang paling cocok. Untuk input suara, model Whisper digunakan untuk mentranskripsi nyanyian menjadi teks sebelum diproses. Selain fitur pencarian utama, MeloDetect juga menyediakan sistem rekomendasi lagu serupa, fitur eksplorasi musik berdasarkan mood atau artis, serta dashboard visualisasi data, yang semuanya disajikan dalam antarmuka interaktif yang dibangun dengan Streamlit.
Description
MeloDetect adalah aplikasi berbasis Artificial Intelligence yang mampu mengidentifikasi judul dan artis lagu hanya dari potongan lirik teks maupun suara pengguna.
Proyek ini mengimplementasikan metode TF-IDF (Term Frequency–Inverse Document Frequency) dan Cosine Similarity untuk menghitung tingkat kemiripan antar lirik dalam dataset. Aplikasi ini juga dilengkapi dengan dashboard analitik menggunakan Streamlit, yang menampilkan visualisasi distribusi mood lagu, word cloud, serta fitur rekomendasi lagu serupa berdasarkan kemiripan konten lirik.
=========================================================== Fitur Utama =======================================================
1. Pencarian Lagu Multi-Modal: Ini adalah fungsi inti aplikasi, memungkinkan pengguna menemukan lagu dengan dua cara yang fleksibel:
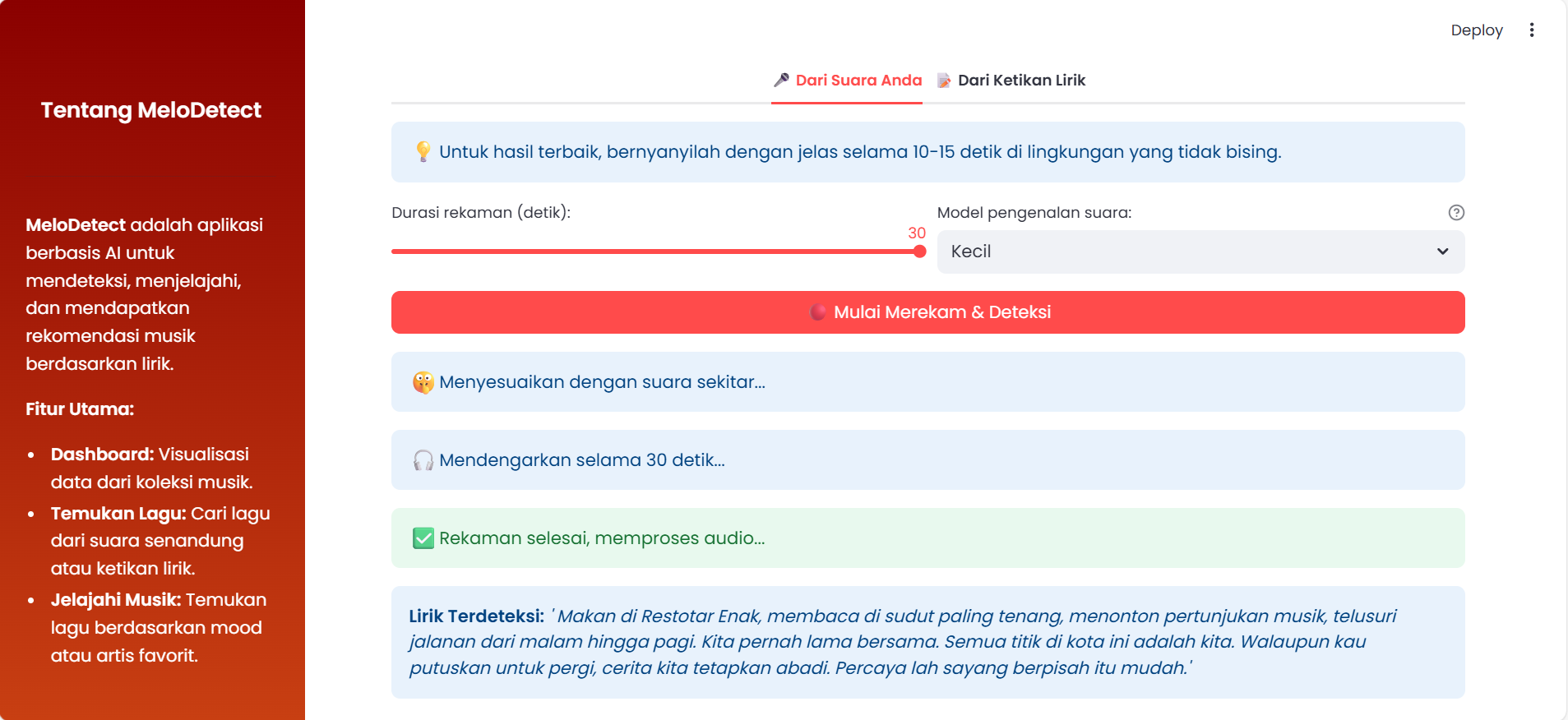
- Pencarian via Suara: Pengguna dapat merekam senandung atau nyanyian singkat. Sistem akan mengubah rekaman suara menjadi teks dan mencocokkannya dengan database lirik.
- Pencarian via Teks: Pengguna dapat mengetikkan sepenggal lirik yang mereka ingat untuk menemukan lagu yang dicari.
2. Rekomendasi Lagu Berbasis Konten: Setelah sebuah lagu berhasil diidentifikasi, aplikasi tidak berhenti di situ. Sistem secara otomatis memberikan rekomendasi lagu-lagu lain yang memiliki kemiripan lirik tertinggi, membantu pengguna menemukan musik baru yang sejenis.
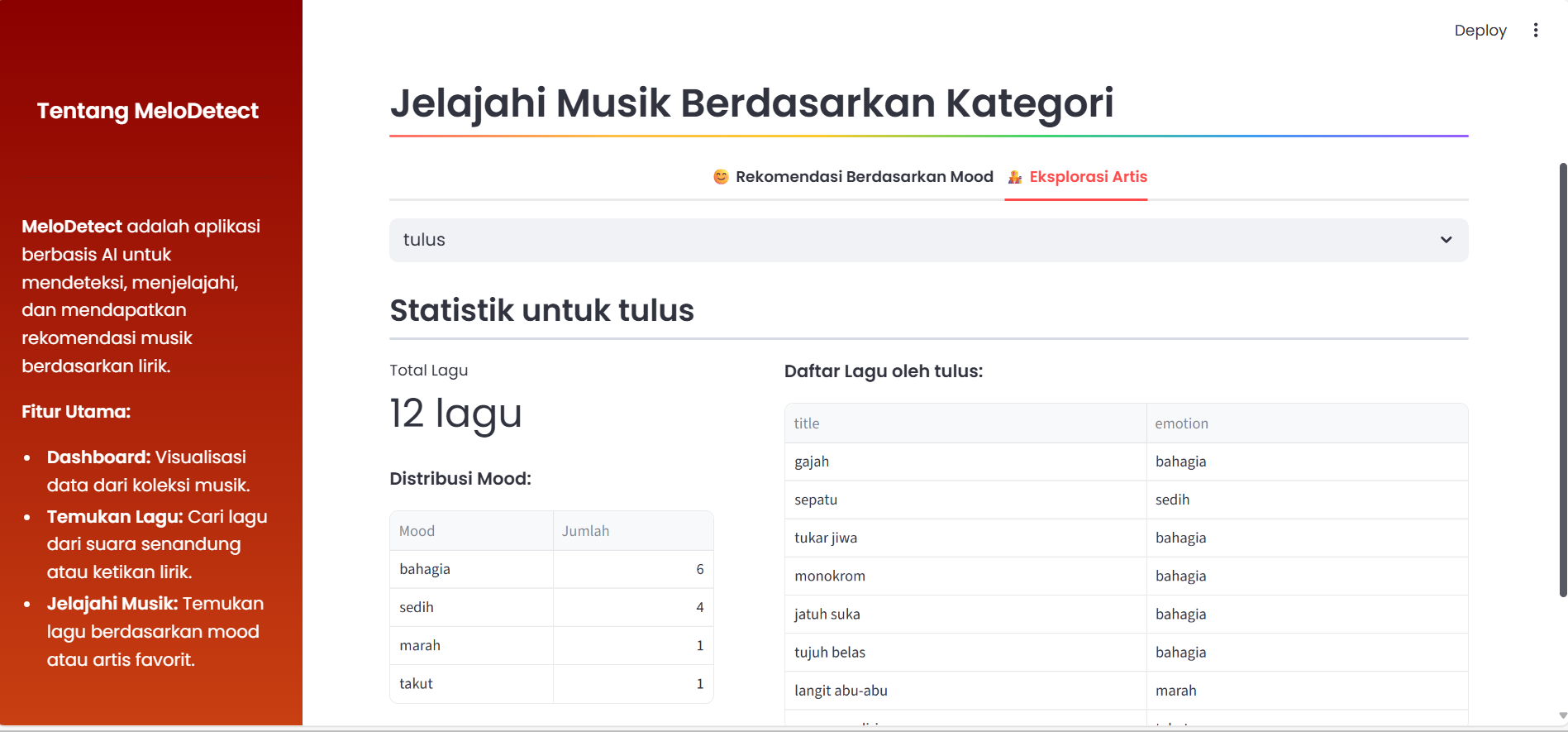
3. Eksplorasi Musik Terkurasi: Fitur ini memungkinkan pengguna menjelajahi koleksi lagu berdasarkan kategori tertentu:
- Rekomendasi Berdasarkan Mood: Pengguna dapat memilih sebuah mood (misalnya: bahagia, sedih) dan aplikasi akan menampilkan daftar lagu acak yang sesuai dengan mood tersebut.
- Eksplorasi Berdasarkan Artis: Pengguna dapat memilih nama artis untuk melihat semua lagu dari artis tersebut yang ada di dalam dataset beserta statistik ringkasnya.
4. Dashboard Visualisasi Data: Memberikan wawasan tentang dataset musik yang digunakan melalui visualisasi yang informatif:
- Metrik Utama: Menampilkan ringkasan jumlah total lagu, artis unik, dan kategori mood.
- Grafik Interaktif: Menyajikan distribusi lagu berdasarkan mood dan daftar artis paling produktif dalam bentuk diagram batang.
- Word Cloud: Visualisasi kata-kata yang paling sering muncul di seluruh lirik dalam dataset, memberikan gambaran umum tentang tema lirik.
=================================================== Teknologi yang Digunakan ================================================
- Bahasa Pemrograman: Python
- Analisis & Pengolahan Data: Pandas, NumPy
- Machine Learning & NLP: Scikit-learn (untuk TF-IDF & Cosine Similarity)
- Pengembangan Aplikasi Web: Streamlit
- Pengenalan Suara: SpeechRecognition (dengan model Whisper)
- Visualisasi Data: Matplotlib, WordCloud
- Lingkungan Pengembangan: Google Colaboratory (untuk pemodelan), Visual Studio Code (untuk aplikasi)
========================================================= Tahapan Proyek =====================================================
1. Pengumpulan dan Persiapan Data
Langkah awal adalah mengumpulkan dataset lirik lagu. Dataset diperoleh dari platform Kaggle, yang berisi kumpulan lagu dengan atribut seperti judul, artis, lirik lengkap, dan kategori emosi/mood. Data dalam format .csv dimuat ke dalam lingkungan kerja Google Colaboratory menggunakan library Pandas untuk dianalisis dan diproses lebih lanjut.

2. Pra-pemrosesan dan Pembersihan Teks (Text Preprocessing)
Kualitas data lirik sangat menentukan akurasi model. Oleh karena itu, dilakukan serangkaian proses pembersihan pada data teks lirik untuk menstandarisasi isinya.
a. Penghapusan Data Tidak Relevan: Kolom yang tidak diperlukan dan baris data yang memiliki nilai kosong (terutama pada kolom lirik) dibuang untuk menjaga integritas data.
b. Normalisasi Teks: Sebuah fungsi khusus dibuat untuk membersihkan setiap lirik, yang mencakup:
- Case Folding: Mengubah seluruh teks menjadi huruf kecil untuk menyeragamkan kata (misal: "Cinta" dan "cinta" dianggap sama).
- Punctuation Removal: Menghapus semua tanda baca (seperti titik, koma, tanda tanya) yang tidak memiliki makna dalam konteks pencocokan kata.
- Number Removal: Menghapus angka dari lirik.
- Whitespace Removal: Menghilangkan spasi berlebih di awal, akhir, dan tengah teks.
c. Hasil: Proses ini menghasilkan kolom baru bernama cleaned_lyrics yang siap untuk diolah oleh model.

3. Ekstraksi Fitur dengan TF-IDF
Setelah lirik bersih, tahap selanjutnya adalah mengubah teks menjadi representasi numerik (vektor) yang dapat dipahami oleh mesin.
- Vektorisasi TF-IDF: Metode TF-IDF digunakan untuk mengubah kumpulan lirik menjadi sebuah matriks. TF-IDF bekerja dengan memberikan bobot pada setiap kata. Kata yang sering muncul dalam satu lirik tetapi jarang muncul di lirik lainnya akan mendapatkan bobot yang tinggi, menandakan bahwa kata tersebut sangat representatif untuk lirik tersebut.
- Pembuatan Matriks: Library Scikit-learn digunakan untuk menginisialisasi TfidfVectorizer dan menerapkannya pada kolom cleaned_lyrics. Hasilnya adalah sebuah Matriks TF-IDF di mana setiap baris mewakili satu lagu dan setiap kolom mewakili sebuah kata unik dari seluruh kosakata lirik.

4. Serialisasi Model dan Data (Model Persistence)
Untuk memisahkan proses pelatihan dan penggunaan model, objek-objek penting disimpan ke dalam file. Penyimpanan Objek: Menggunakan library Pickle, tiga file utama disimpan:
- tfidf_vectorizer.pkl: Objek vectorizer yang telah "belajar" dari seluruh kosakata lirik.
- tfidf_matrix.pkl: Matriks TF-IDF yang berisi representasi vektor dari semua lagu.
- lirik_data.pkl: DataFrame Pandas yang berisi data lagu yang sudah bersih.
Tujuan: File-file ini memungkinkan aplikasi web untuk memuat model yang sudah jadi tanpa perlu melatih ulang setiap kali dijalankan.

5. Pengembangan Aplikasi Web dengan Streamlit
Tahap terakhir adalah membangun antarmuka pengguna (UI) yang interaktif dan ramah pengguna agar sistem dapat diakses dengan mudah.
a. Framework: Streamlit dipilih karena kemudahannya dalam mengubah skrip data menjadi aplikasi web yang fungsional.
b. Desain Antarmuka: Aplikasi didesain dengan beberapa tab untuk memisahkan fungsionalitas:
- Dashboard: Menampilkan visualisasi data seperti total lagu, distribusi mood, dan artis paling produktif menggunakan metrik dan grafik.
- Temukan Lagu: Menyediakan dua metode input (input suara dan input teks)
- Input Suara: Menggunakan library SpeechRecognition, pengguna dapat menyanyikan atau mengucapkan lirik, yang kemudian diubah menjadi teks dan digunakan untuk pencarian.
- Input Teks: Pengguna dapat mengetikkan lirik secara manual.
- Jelajahi Musik: Memungkinkan pengguna menemukan lagu berdasarkan mood atau melihat semua lagu dari artis tertentu.
- Integrasi Model: Aplikasi memuat file .pkl yang telah disimpan sebelumnya untuk menjalankan fungsi pencarian dan rekomendasi secara real-time.










LINK Google Colab: https://colab.research.google.com/drive/1GbhXCke57LoR_qx1Y7-e7UAzVwZS0b1i?usp=sharing
LINK GitHub: https://github.com/indahaha/MeloDetection
Informasi Course Terkait
Kategori: Data Science / Big DataCourse: Master Class Data Science



