
Kompleksitas Algoritma Huda Rasyad Wicaksono
Huda Rasyad Wicaksono


Summary
Laporan ini menganalisis dua algoritma yang diberikan, menghitung jumlah iterasi dan menyajikan perhitungan kompleksitas secara rinci. Simulasi menggunakan array data sensor acak menunjukkan bagaimana pendekatan iteratif dan rekursif bekerja pada ukuran input berbeda. Grafik memperlihatkan perbandingan jumlah iterasi dan waktu eksekusi, serta menunjukkan keunggulan divide & conquer dalam efisiensi. Analisis dilengkapi evaluasi penggunaan algoritma dalam konteks IoT, mempertimbangkan kendala perangkat edge dan server cloud, serta rekomendasi optimasi seperti prefix sum.
Description
Analisis Kompleksitas Algoritma dan Pengolahan Data Sensor IoT
Pembukaan
Pada mata kuliah Kompleksitas Algoritma, mahasiswa ditantang untuk tidak hanya menulis kode, tetapi juga memahami bagaimana kinerja kode tersebut ketika ukuran input bertambah. Ketika seorang programer hanya fokus pada “program jalan atau tidak”, ia sering lupa mempertimbangkan waktu eksekusi atau penggunaan sumber daya. Padahal, dua algoritma yang melakukan tugas sama bisa memiliki waktu eksekusi yang sangat berbeda. Penilaian tugas kali ini meminta kita menganalisis dua algoritma sederhana serta membandingkan pendekatan iteratif dan rekursif dalam konteks pengolahan data sensor Internet of Things (IoT). Dalam pembahasan berikut saya akan menggunakan bahasa yang sederhana dengan beberapa analogi sehari‑hari untuk memudahkan pemahaman.
Penjelasan algoritma dan logika kerja
Algoritma 1 dan Algoritma 2 (Soal dasar kompleksitas)
Algoritma pertama diberi nama FUN(int n) dan menyiapkan variabel m = 2000. Ia menjalankan dua loop bersarang: loop luar berjalan dari i = 0 hingga i < n/2, dan loop dalam berjalan dari j = 0 hingga j < m*1000. Di dalam loop dalam terdapat pernyataan Console.print(i+j) yang dicetak setiap iterasi. Karena nilai m dan pengali 1000 bersifat konstanta, jumlah iterasi loop dalam tidak dipengaruhi oleh nilai n. Loop luar seolah‑olah seperti orang yang menghitung apel satu per satu, sedangkan loop dalam menyerupai jam alarm yang berbunyi sebanyak 2 juta kali untuk setiap apel yang dihitung.
Pada Algoritma 2, variabel m bukanlah konstanta, melainkan dihitung sebagai n/10000. Loop luar masih sama, yaitu dari i = 0 hingga i < n/2. Loop dalam menggunakan variabel j dengan langkah j += 20 sampai j < m. Dengan kata lain, j melompat 20 satuan setiap iterasi. Analoginya seperti seseorang yang menghitung tangga dengan lompatan dua puluh anak tangga sekaligus. Jika n sangat kecil (misal n = 10 atau 20), pembagian n/10000 menghasilkan 0 karena tipe datanya integer. Akibatnya loop j tidak pernah berjalan dan perintah Console.print(i+j) tidak pernah dieksekusi. Namun untuk nilai n besar, nilai m membesar secara proporsional terhadap n, sehingga loop dalam perlahan‑lahan memiliki beberapa iterasi.
Algoritma kumulatif_iteratif dan kumulatif_rekursif (Soal IoT)
Pada kasus pengolahan data sensor, kita memiliki dua pendekatan untuk menghitung total kumulatif dari array sensor Data:
Pendekatan Iteratif: Fungsi kumulatif_iteratif(Data, n) menginisialisasi total = 0. Kemudian, untuk setiap indeks i dari 0 sampai n – 1, ia menjalankan loop kedua dari j = 0 sampai i. Setiap nilai Data[j] ditambahkan ke total. Dengan pola ini, elemen pada indeks 0 dijumlahkan sebanyak n kali, elemen pada indeks 1 dijumlahkan sebanyak n – 1 kali, dan seterusnya. Kompleksitasnya mirip segitiga angka, karena jumlah iterasi terbentuk dari deret 1 + 2 + … + n, sehingga tumbuh secara kuadrat (∼ n²). Algoritma ini sederhana tetapi boros operasi, cocok untuk perangkat kecil jika ukuran data sangat terbatas.
Pendekatan Rekursif: Fungsi kumulatif_rekursif(Data, n) bekerja dengan membagi array menjadi dua bagian (divide & conquer). Jika panjang array hanya satu, fungsi mengembalikan nilai tunggal tersebut. Jika lebih, ia membagi array menjadi bagian kiri dan kanan, lalu memanggil dirinya sendiri pada kedua bagian tersebut. Hasil akhirnya diperoleh dengan menambahkan hasil kiri dan kanan. Dengan strategi ini, masalah besar dipecah menjadi beberapa sub‑masalah kecil hingga mencapai basis kasus (n = 1). Pendekatan ini mirip membagi tugas menghitung ke beberapa pekerja: setiap pekerja menghitung sebagian data, lalu hasilnya dijumlahkan. Waktu eksekusinya mengikuti relasi rekurens T(n) = 2T(n/2) + O(1), yang menurut Master Theorem menghasilkan kompleksitas linier O(n). Materi pembahasan master theorem menunjukkan bahwa untuk relasi T(n) = a · T(n/b) + f(n), bila f(n) lebih kecil dari n^log_b a maka T(n) tumbuh sebesar n^log_b a. Dalam kasus kita a = 2, b = 2 dan f(n) = O(1), sehingga log_b a = 1 dan T(n) ∈ Θ(n).
Perhitungan jumlah iterasi (n = 10 dan n = 20)
Algoritma 1
Pada Algoritma 1, jumlah iterasi dapat dihitung langsung dari ukuran loop. Loop luar melakukan n/2 iterasi, sedangkan loop dalam melakukan m × 1000 iterasi dengan m = 2000. Jumlah total pernyataan Console.print(i+j) adalah:
Untuk n = 10: loop luar berjalan 5 kali dan loop dalam berjalan 2 000 × 1 000 = 2 000 000 kali. Sehingga total eksekusi = 5 × 2 000 000 = 10 000 000.
Untuk n = 20: loop luar berjalan 10 kali, total eksekusi = 10 × 2 000 000 = 20 000 000.
Jumlah iterasi meningkat secara linier terhadap n, karena loop dalam memiliki ukuran tetap. Deret aritmetika ini sesuai dengan contoh loop kuadratik di mana total iterasi sebanding dengan jumlah elemen input, tetapi dalam kasus ini faktor skala m*1000 adalah konstanta sehingga kompleksitasnya linier.
Algoritma 2
Di Algoritma 2, nilai m dihitung sebagai n/10000 (pembagian bulat). Pada n = 10 dan n = 20, pembagian tersebut menghasilkan 0 sehingga loop j tidak pernah dijalankan. Loop luar memang berjalan (i dari 0 hingga n/2 – 1), namun karena loop dalam tidak dieksekusi, pernyataan Console.print(i+j) tidak dipanggil sama sekali. Total iterasi yang mencetak sesuatu = 0. Namun bila n sangat besar, misalnya 1 000 000, kita mendapatkan m = 1000000 / 10000 = 100. Loop j dengan langkah +20 akan berjalan sekitar 5 kali untuk setiap nilai i, sehingga jumlah total pernyataan print mencapai (n/2)×(m/20) ≈ n²/400 000.
Analisis kompleksitas (Big‑O, Big‑Ω, Big‑Θ)
Algoritma 1
Fungsi waktu eksekusi Algoritma 1 dapat dinyatakan sebagai T₁(n) = (n/2) × (m × 1000) + c, dengan m konstanta. Suku dominan adalah c₁ × n, sehingga T₁(n) berada dalam kelas Θ(n). Karena loop luar selalu berjalan setengah dari ukuran n, kita juga dapat menuliskan batas bawah Ω(n) dan batas atas O(n). Dalam hal pertumbuhan asimptotik, Algoritma 1 termasuk linear time complexity.
Algoritma 2
Untuk Algoritma 2, m = n/10000 dan loop j melangkah 20 per iterasi. Jumlah iterasi total dapat ditulis sebagai T₂(n) = (n/2) × ((m + 19) // 20). Jika n jauh lebih kecil dari 10 000, nilai m = 0 sehingga T₂(n) ≈ 0. Namun, untuk n besar, m ≈ n/10000 sehingga T₂(n) ≈ (n/2) × (n/200000) = (1/400000) × n². Konstanta 1/400 000 tidak mempengaruhi notasi asimptotik; karenanya T₂(n) ∈ Θ(n²), Ω(n²), dan O(n²). Hal ini sejalan dengan teori bahwa nested loop yang setiap indeks bergantung pada ukuran input menghasilkan pertumbuhan kuadrat.
Dalam perbandingan pertumbuhan, Algoritma 1 akan tetap lebih cepat untuk n kecil sampai cukup besar, karena perhitungan Algoritma 2 meningkat kuadrat meski faktor skalanya kecil. Apabila n = 10⁶, Algoritma 1 memerlukan (10⁶/2)×2 000 000 = 10¹² langkah, sedangkan Algoritma 2 sekitar (10⁶)²/400 000 = 2,5 × 10⁶ langkah. Ini menunjukkan bahwa pertumbuhan kuadrat Algoritma 2 bisa lebih efisien karena faktor pembagi yang besar, tetapi bila n terus meningkat, suku kuadrat akan mendominasi. Konsep Master Theorem membantu menganalisis relasi rekursif seperti ini; teorema tersebut menyatakan bahwa untuk T(n) = a T(n/b) + f(n), jika f(n) tumbuh lebih lambat dari n^{log_b a}, maka T(n) ∈ Θ(n^{log_b a}).
Simulasi dan visualisasi hasil eksekusi
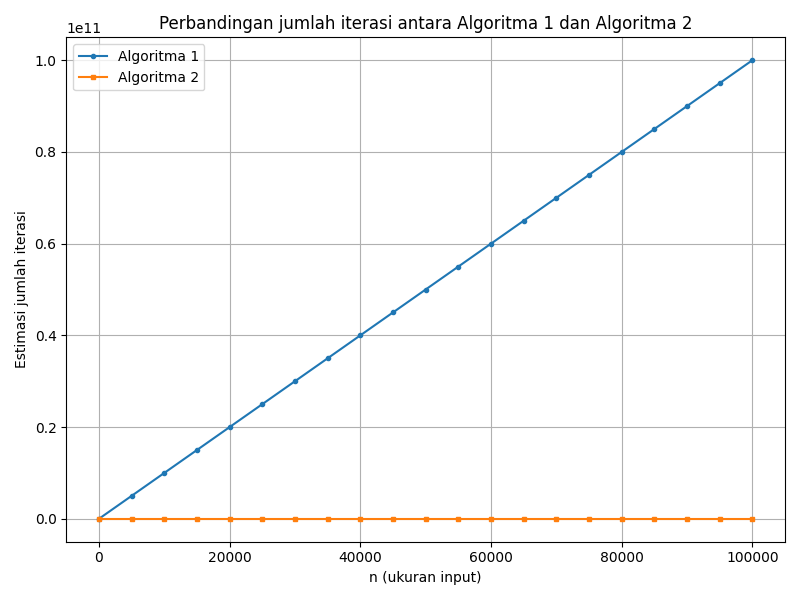
Untuk memperkuat analisis, saya melakukan simulasi menggunakan Python. Skrip ini menghitung jumlah iterasi perkiraan untuk Algoritma 1 dan 2 pada berbagai nilai n hingga 100 000. Gambar berikut memperlihatkan hasilnya:

Pada grafik di atas, garis biru mewakili Algoritma 1. Garis ini hampir lurus karena jumlah iterasi bertambah proporsional terhadap n. Garis oranye mewakili Algoritma 2 yang tampak datar untuk n di bawah 10 000 (karena loop dalam tidak berjalan). Setelah n cukup besar, garis ini mulai menaik mengikuti kurva kuadrat, meskipun kemiringannya relatif landai karena faktor 1/400 000.
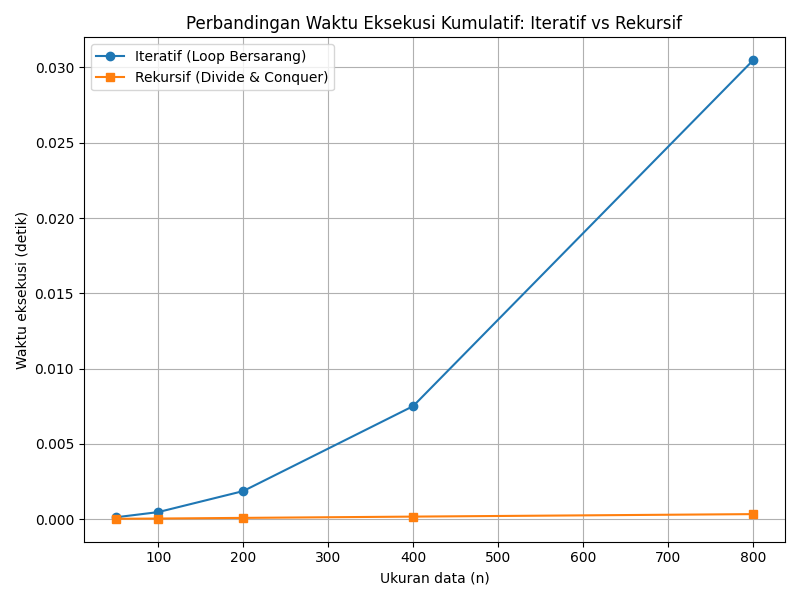
Untuk kasus IoT, saya membuat array sensor acak yang merepresentasikan suhu/polusi dan menjalankan kedua fungsi kumulatif_iteratif dan kumulatif_rekursif pada data berukuran 50 hingga 800. Waktu eksekusi diukur menggunakan modul time. Grafik berikut menunjukkan perbandingannya:

Terlihat jelas bahwa waktu eksekusi kumulatif_iteratif meningkat drastis seiring bertambahnya ukuran data. Misalnya, pada 800 data, waktu eksekusi mencapai sekitar 0,03 detik. Sebaliknya, fungsi rekursif divide & conquer hanya membutuhkan sekitar 0,00034 detik pada ukuran yang sama. Perbedaan ini menggambarkan pertumbuhan O(n²) vs O(n) secara nyata.
Evaluasi algoritma (kasus IoT: iteratif vs rekursif)
Ketika diaplikasikan pada sistem IoT, pemilihan algoritma harus mempertimbangkan keterbatasan perangkat dan kebutuhan waktu respon. Artikel Milvus menekankan bahwa edge AI diproses langsung di perangkat lokal untuk menghindari latensi jaringan, sedangkan cloud AI memanfaatkan server pusat yang berdaya besar. Perbedaan utama lainnya adalah sumber daya: edge devices mempunyai keterbatasan daya, memori dan kemampuan pemrosesan, sehingga pengembang harus mengoptimalkan algoritma agar efisien.
Kasus terbaik, rata‑rata, dan terburuk
Untuk fungsi kumulatif_iteratif, jumlah iterasi selalu sama terlepas dari nilai data; tidak ada kondisi yang dapat menghentikan loop lebih cepat. Baik kasus terbaik, rata‑rata maupun terburuk adalah sama dan berada pada kelas O(n²). Sebaliknya, kumulatif_rekursif akan selalu memecah array menjadi dua bagian sampai ukuran 1, sehingga kompleksitasnya O(n) pada semua kasus.
Penentuan penggunaan pada perangkat edge dan server cloud
Jika sistem harus memproses 1 juta data sensor per jam, pertimbangkan bahwa kumulatif_iteratif memerlukan ~0,5 × 10¹² operasi untuk n = 1 000 000 (serupa dengan Algoritma 1). Operasi sebanyak itu akan menguras CPU dan baterai edge device serta menimbulkan latensi tinggi. Algoritma rekursif memerlukan O(n) penambahan (sekitar satu juta operasi), jauh lebih ringan. Oleh karena itu, secara teknis pendekatan rekursif divide & conquer lebih sesuai dijalankan di server cloud yang memiliki kemampuan paralel dan dapat membagi pekerjaan pada banyak core. Walaupun rekursi membutuhkan memori stack, server memiliki memori lebih besar sehingga overhead ini tidak menjadi masalah. Selain itu, pembagian tugas memungkinkan pemrosesan parallel untuk waktu respon rendah. Untuk perangkat edge dengan keterbatasan memori dan daya, penggunaan algoritma iteratif bersarang jelas tidak efisien karena konsumsi energi dan latensi tinggi; sebaiknya algoritma dioptimalkan atau memproses bagian data lebih kecil.
Implikasi terhadap waktu respon, konsumsi daya, dan skalabilitas
Waktu respon: Algoritma O(n²) menyebabkan waktu respon meningkat tajam ketika jumlah sensor bertambah; ini dapat menghambat sistem pemantauan real‑time. Algoritma O(n) atau O(n log n) memberikan waktu respon lebih cepat dan konsisten.
Konsumsi daya: Loop bersarang membuat prosesor bekerja lebih lama dan mengkonsumsi lebih banyak energi, yang buruk untuk baterai edge devices. Divide & conquer mengurangi jumlah operasi sehingga lebih hemat daya.
Skalabilitas: Pertumbuhan kuadrat tidak berskala untuk ribuan sensor. Di sisi lain, algoritma O(n) tetap dapat dioptimalkan dengan memanfaatkan multi‑core di cloud sehingga mampu menangani lonjakan jumlah sensor.
Optimasi yang disarankan
Untuk meningkatkan efisiensi, sistem dapat mengganti algoritma iteratif dengan algoritma prefix sum satu pass (memakai satu loop). Algoritma prefix sum menghitung total += Data[i] untuk setiap elemen sehingga kompleksitasnya O(n). Alternatif lainnya adalah menggunakan struktur data seperti Fenwick Tree atau Segment Tree yang dapat menghitung kumulatif dan update dalam O(log n). Dengan demikian, total komputasi berkurang dari O(n²) menjadi O(n) atau O(n log n), memberikan keuntungan kecepatan dan hemat energi.
Kesimpulan dan rekomendasi
Analisis dua algoritma sederhana menunjukkan betapa perbedaan kecil dalam penulisan kode berdampak besar pada kinerja. Algoritma 1 memanfaatkan konstanta dan menghasilkan kompleksitas linier O(n); Algoritma 2 bergantung pada n dan menghasilkan kompleksitas kuadrat O(n²) dengan faktor skala kecil. Simulasi memperlihatkan bahwa pada ukuran input tertentu, Algoritma 2 bisa lebih efisien karena konstanta pembaginya besar, tetapi secara teoretis pertumbuhan n² akan mendominasi seiring n bertambah.
Dalam kasus pengolahan data sensor, kumulatif_iteratif yang menggunakan loop bersarang membebani perangkat edge jika data besar, sedangkan kumulatif_rekursif yang membagi data ke sub‑bagian memberikan kinerja jauh lebih baik (O(n)). Hasil pengukuran waktu eksekusi mendukung hal ini: pada 800 elemen, rekursi 90 kali lebih cepat daripada iterasi. Berdasarkan analisis ini, rekomendasi saya adalah:
Gunakan pendekatan divide & conquer atau algoritma prefix sum pada server cloud untuk memproses data sensor besar. Pendekatan ini memanfaatkan kemampuan paralel server dan memberikan kompleksitas linier.
Untuk perangkat edge, hindari loop bersarang O(n²). Jika data yang diproses sedikit (misalnya ratusan sampel), algoritma iteratif mungkin masih dapat diterima karena implementasinya sederhana. Namun untuk jutaan data, lebih baik melakukan agregasi sederhana terlebih dahulu di edge (misal menghitung rata‑rata harian) dan mengirim data ke server untuk pemrosesan lebih lanjut.
Selalu analisis kompleksitas sebelum memilih algoritma. Pertumbuhan asimptotik memberikan gambaran bagaimana program berperilaku ketika skala sistem meningkat. Dengan memahami konsep ini, kita dapat merancang sistem IoT yang hemat energi, responsif, dan mudah ditingkatkan.
Informasi Course Terkait
Kategori: Algoritma dan PemrogramanCourse: Dasar - Dasar Python



