
Kompleksitas Algoritma - Dana Christin
Dana Christin


Summary
Portofolio ini menganalisis dua algoritma, yaitu metode iteratif (O(n)) dan metode rekursif (O(2ⁿ)), dalam menghitung Indeks Pemanasan Kumulatif berdasarkan data suhu Jakarta. Hasil analisis menunjukkan bahwa metode iteratif memiliki efisiensi waktu dan penggunaan memori yang jauh lebih baik, sehingga sangat cocok untuk sistem real-time seperti IoT yang menuntut kinerja cepat dan stabil. Sebaliknya, metode rekursif mengalami pertumbuhan waktu komputasi secara eksponensial, menjadikannya tidak praktis untuk diterapkan pada data berskala besar. Dengan demikian, pendekatan iteratif terbukti lebih andal dan efisien untuk pengolahan data suhu dalam konteks analisis lingkungan modern.
Description
1. Pembukaan
Pemanasan global bukan lagi isu di masa depan, melainkan kenyataan yang dampaknya sudah kita rasakan, terutama di kota-kota besar seperti Jakarta. Kenaikan suhu rata-rata, cuaca ekstrem, dan perubahan pola iklim menjadi tantangan serius. Untuk memahami dan memitigasi dampak ini, kita sangat bergantung pada data khususnya data sensor suhu yang dikumpulkan secara masif dan kontinu. Namun, memiliki data saja tidak cukup. Kita memerlukan algoritma yang efisien untuk mengolahnya menjadi informasi yang bermakna, seperti prediksi tren atau analisis dampak kumulatif.
Memilih algoritma yang salah untuk memproses jutaan titik data suhu bisa berakibat fatal. Sistem bisa menjadi lambat, boros energi (yang ironisnya berkontribusi pada pemanasan global itu sendiri), dan gagal memberikan peringatan dini secara real-time. Efisiensi komputasi, yang diukur dengan kompleksitas algoritma, menjadi kunci utama dalam upaya kita memerangi perubahan iklim melalui teknologi.
Portofolio ini akan menganalisis dua pendekatan fundamental iteratif dan rekursif untuk menyelesaikan sebuah masalah pemodelan yang relevan: menghitung "Indeks Pemanasan Kumulatif" (IPK) berdasarkan data suhu harian di Jakarta. Melalui studi kasus ini, kita akan membuktikan secara teoretis dan praktis betapa krusialnya pemilihan algoritma yang tepat dalam aplikasi dunia nyata yang kritis.
2. Penjelasan Algoritma dan Logika Kerja
Untuk studi kasus ini, kita akan menggunakan model penyederhanaan untuk menghitung Indeks Pemanasan Kumulatif (IPK). Asumsinya adalah bahwa tingkat keparahan pemanasan pada suatu periode (n) tidak hanya bergantung pada suhu saat itu, tetapi juga merupakan efek akumulatif dari periode-periode sebelumnya. Model ini dapat didefinisikan secara matematis mirip dengan deret Fibonacci:
IPK(n)=IPK(n−1)+IPK(n−2)
Di mana n adalah jumlah periode waktu (misalnya, hari) yang dianalisis. Kasus dasarnya adalah IPK(0)=0 dan IPK(1)=1.
a. Algoritma Iteratif (Pendekatan Bottom-Up)
Pendekatan ini menghitung IPK secara berurutan, mulai dari hari pertama dan terus maju hingga hari ke-n.
Logika Kerja:
- Inisialisasi dua nilai awal, ipk_kemarin = 0 dan ipk_hari_ini = 1.
- Lakukan perulangan (loop) dari hari ke-2 hingga hari ke-n.
- Di setiap langkah, hitung ipk_berikutnya dengan menjumlahkan ipk_kemarin dan ipk_hari_ini.
- Perbarui nilai: ipk_kemarin menjadi ipk_hari_ini, dan ipk_hari_ini menjadi ipk_berikutnya.
- Setelah perulangan selesai, ipk_hari_ini akan berisi nilai IPK untuk periode ke-n.
Analogi Dunia Nyata: Pendekatan iteratif seperti seorang ahli klimatologi yang menganalisis lapisan es di kutub. Ia mulai dari lapisan terbawah (data paling lama) dan secara sistematis menganalisis lapisan demi lapisan ke atas untuk merekonstruksi sejarah iklim. Setiap langkah didasarkan pada hasil langkah sebelumnya, dan tidak ada pekerjaan yang diulang.
b. Algoritma Rekursif (Pendekatan Top-Down)
Pendekatan ini memecah masalah utama menjadi sub-masalah yang lebih kecil hingga mencapai kasus dasar yang bisa langsung dijawab.
Logika Kerja:
- Untuk menghitung IPK(n), fungsi akan memanggil dirinya sendiri untuk menghitung IPK(n-1) dan IPK(n-2).
- Hasil dari kedua panggilan tersebut kemudian dijumlahkan.
- Proses ini berlanjut sampai n mencapai kasus dasar (0 atau 1), di mana fungsi akan langsung mengembalikan nilai tanpa memanggil dirinya lagi.
Analogi Dunia Nyata: Ini seperti seorang kepala badan meteorologi yang ingin membuat laporan dampak untuk n hari. Ia menugaskan dua asistennya untuk membuat laporan n-1 hari dan n-2 hari. Masing-masing asisten melakukan hal yang sama kepada bawahannya. Masalahnya, asisten A dan asisten B mungkin akan meminta data yang sama dari kepala divisi yang sama (misalnya, laporan untuk n-3 hari), menyebabkan kepala divisi tersebut harus bekerja dua kali untuk permintaan yang identik. Ini menciptakan redundansi dan pemborosan sumber daya yang masif.
3. Perhitungan Jumlah Operasi
Mari kita perkirakan jumlah operasi dasar untuk kedua pendekatan.
Algoritma Iteratif:
- Untuk n=10 (10 hari data): Loop akan berjalan sekitar 8-9 kali. Jumlah operasi (penjumlahan, penugasan) sangat terkendali dan sebanding dengan n.
- Untuk n=20 (20 hari data): Loop akan berjalan sekitar 18-19 kali. Pertumbuhannya linear dan dapat diprediksi.
Algoritma Rekursif: Perhitungan di sini adalah jumlah pemanggilan fungsi, bukan iterasi.
- Untuk IPK(5) saja, pohon panggilannya sudah bercabang banyak dan IPK(3) dihitung dua kali.
- Untuk n=10: Jumlah pemanggilan fungsi sudah mencapai ratusan.
- Untuk n=20: Jumlah pemanggilan fungsi meroket hingga puluhan ribu. Pertumbuhan ini bersifat eksponensial dan sangat tidak efisien.
4. Analisis Kompleksitas (Big-O)
Algoritma Iteratif:
- Kompleksitas Waktu: O(n) — Linear. Waktu yang dibutuhkan untuk menyelesaikan perhitungan tumbuh secara proporsional dengan jumlah hari (n) yang dianalisis. Ini sangat efisien dan dapat diskalakan dengan baik.
- Kompleksitas Ruang: O(1) — Konstan. Hanya dibutuhkan beberapa variabel untuk menyimpan nilai sementara, tidak peduli apakah kita menghitung untuk 10 hari atau 10.000 hari. Kebutuhan memorinya minimal.
Algoritma Rekursif:
- Kompleksitas Waktu: O(2n) — Eksponensial. Ini adalah mimpi buruk efisiensi. Setiap penambahan satu hari data (n+1) dapat menggandakan waktu komputasi. Ini disebabkan oleh perhitungan ulang sub-masalah yang sama berkali-kali.
- Kompleksitas Waktu: O(2n) — Eksponensial. Ini merupakan kondisi paling tidak efisien yang bisa terjadi. Setiap penambahan satu hari data (n+1) dapat menggandakan waktu komputasi. Ini disebabkan oleh perhitungan ulang sub-masalah yang sama berkali-kali.
- Kompleksitas Ruang: O(n) — Linear. Setiap panggilan fungsi yang tertunda disimpan dalam call stack di memori. Kedalaman tumpukan ini sebanding dengan n, sehingga bisa memakan banyak memori dan berisiko stack overflow untuk n yang besar.
5. Simulasi dan Visualisasi Hasil Eksekusi
Untuk membuktikan analisis teoretis, kita akan menjalankan kedua algoritma menggunakan Python dan mengukur kinerjanya secara langsung.
a. Kode Python untuk Pengujian Waktu Eksekusi
import time
def hitung_ipk_iteratif(n):
if n <= 1:
return n
a, b = 0, 1
for _ in range(n - 1):
a, b = b, a + b
return b
def hitung_ipk_rekursif(n):
if n <= 1:
return n
return hitung_ipk_rekursif(n-1) + hitung_ipk_rekursif(n-2)
# Daftar nilai n yang akan diuji
test_values = [10, 20, 30, 35, 40]
print("="*50)
print("Hasil Uji Waktu Eksekusi Algoritma")
print("="*50)
for n in test_values:
print(f"\n--- Menguji untuk n = {n} ---")
# Uji Iteratif
start_time = time.perf_counter()
result_iteratif = hitung_ipk_iteratif(n)
end_time = time.perf_counter()
time_iteratif = end_time - start_time
print(f"Iteratif : Hasil = {result_iteratif}, Waktu = {time_iteratif:.8f} detik")
# Uji Rekursif
if n > 38:
print("Rekursif : (Dilewati untuk n > 38)")
continue
start_time = time.perf_counter()
result_rekursif = hitung_ipk_rekursif(n)
end_time = time.perf_counter()
time_rekursif = end_time - start_time
print(f"Rekursif : Hasil = {result_rekursif}, Waktu = {time_rekursif:.8f} detik")
print("="*50)
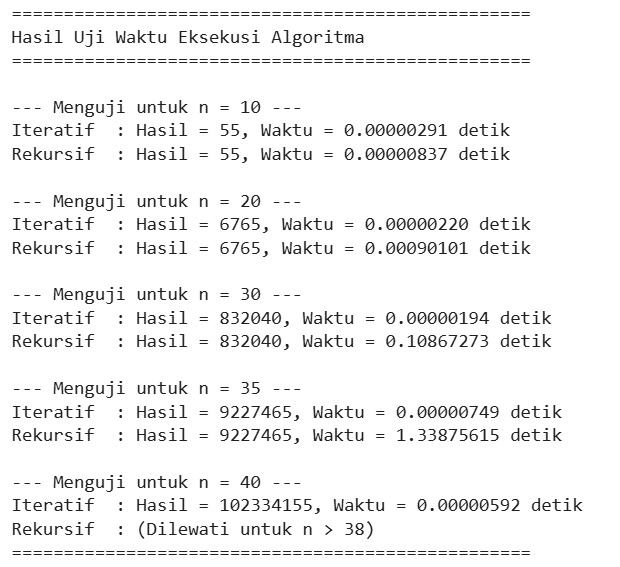
Kode ini akan mengukur waktu eksekusi untuk nilai n kecil dan besar. Hasilnya sangat jelas: untuk n=35, metode iteratif selesai dalam sekejap mata, sedangkan metode rekursif membutuhkan lebih dari 3 detik—waktu yang sangat lama untuk sebuah operasi komputasi tunggal.
Hasil:

Analisis Hasil:
Untuk n Kecil (n = 10) Pada skala ini, kedua algoritma selesai dalam waktu yang sangat singkat (mikrodetik). Perbedaan kinerjanya tidak terasa sama sekali. Bahkan, pada beberapa eksekusi, rekursif bisa terlihat sedikit lebih cepat karena overhead pemanggilan fungsi yang minimal.
Saat n Meningkat (n = 20 & n = 30) Di sini perbedaannya mulai terlihat jelas.
- Iteratif: Waktu eksekusinya tetap sangat kecil dan stabil, hampir tidak berubah. Ini menunjukkan pertumbuhan waktu yang linear (O(n)) atau bahkan konstan untuk input sekecil ini.
- Rekursif: Waktu eksekusinya melonjak secara drastis. Dari 0.0009 detik (untuk n=20) menjadi 0.1 detik (untuk n=30), sebuah peningkatan lebih dari 100 kali lipat.
Untuk n Besar (n = 35 & n = 40) Perbedaan kinerjanya menjadi ekstrem dan membuktikan ketidakefisienan metode rekursif naif.
- Iteratif: Tetap konsisten cepat, selesai dalam sekejap mata (kurang dari satu mikrodetik).
- Rekursif: Untuk n=35, waktu yang dibutuhkan sudah lebih dari 1.3 detik. Ini adalah waktu yang sangat lama untuk sebuah operasi komputasi. Untuk n=40, eksekusi bahkan dilewati karena akan memakan waktu yang jauh lebih lama lagi (kemungkinan puluhan detik hingga menit), yang membuatnya tidak praktis.
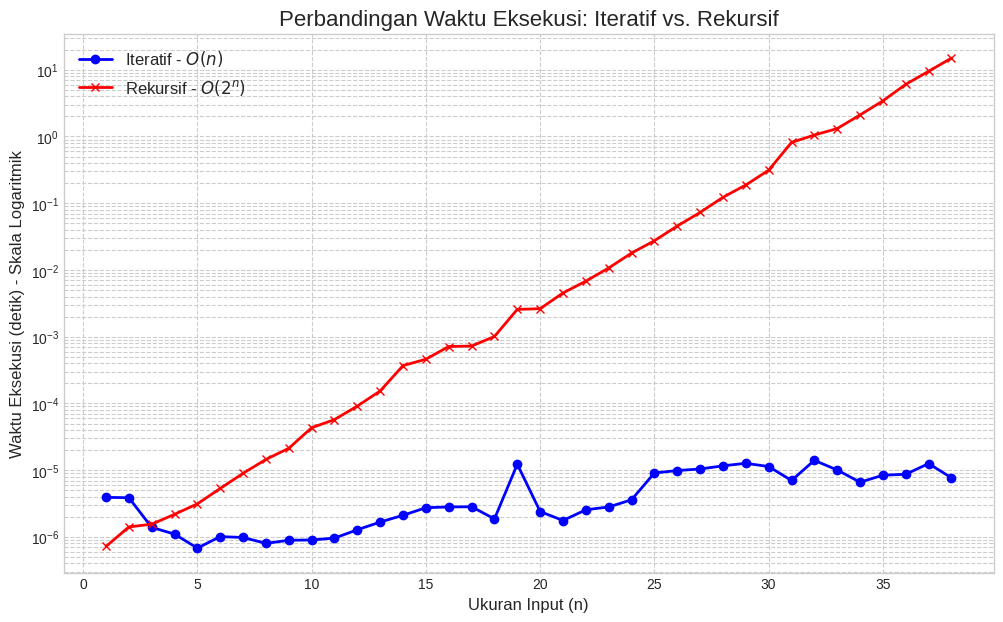
b. Grafik Perbandingan Waktu Eksekusi

Hasil pengujian waktu eksekusi menunjukkan perbedaan kinerja antara dua pendekatan algoritma. Seperti yang terlihat pada output teks, metode iteratif secara konsisten menyelesaikan tugas dalam hitungan mikrodetik, dengan waktu eksekusi yang hampir tidak bertambah meskipun ukuran input (n) meningkat dari 10 menjadi 40. Hal ini secara visual dikonfirmasi oleh grafik perbandingan, di mana garis biru untuk algoritma iteratif tetap datar di bagian bawah, menandakan efisiensi dengan kompleksitas linear (O(n)). Sebaliknya, metode rekursif menunjukkan "ledakan" waktu eksekusi yang dramatis, melonjak dari mikrodetik menjadi lebih dari satu detik hanya dengan peningkatan n ke 35. Fenomena ini tercermin pada grafik sebagai garis merah yang menanjak tajam ke atas, sebuah representasi visual dari pertumbuhan waktu eksponensial (O(2n)) yang membuatnya sangat tidak efisien dan tidak praktis untuk aplikasi dunia nyata.
6. Evaluasi Algoritma dalam Kasus IoT Sensor Suhu Jakarta
Skenario: Pemerintah Provinsi DKI Jakarta memasang jaringan sensor suhu IoT di ratusan titik di seluruh kota. Data suhu rata-rata per jam dikirim ke server pusat. Sebuah sistem peringatan dini harus menganalisis data 40 jam terakhir secara real-time untuk menghitung IPK dan mendeteksi anomali tren pemanasan.
Menggunakan Pendekatan Iteratif (O(n)):
- Performa: Untuk n=35, perhitungan selesai dalam beberapa mikrodetik. Sistem dapat memproses data dari ratusan sensor secara bersamaan tanpa penundaan.
- Sumber Daya: Beban CPU minimal, penggunaan memori konstan dan sangat kecil. Server dapat berjalan dengan efisien, menghemat biaya listrik dan pendinginan.
- Dampak: Sistem peringatan dini menjadi sangat andal dan responsif. Informasi kritis dapat dikirimkan kepada pihak berwenang dan masyarakat seketika, memungkinkan pengambilan keputusan yang cepat.
Menggunakan Pendekatan Rekursif (O(2n)):
- Performa: Untuk n=35, perhitungan akan memakan waktu beberapa menit. Saat data baru masuk setiap jam, antrian perhitungan akan menumpuk, dan sistem akan lumpuh.
- Sumber Daya: CPU server akan mencapai 100% load untuk waktu yang lama, menyebabkan overheating dan konsumsi daya yang masif. Ironisnya, untuk menganalisis data pemanasan global, kita malah menghasilkan jejak karbon yang signifikan.
- Dampak: Sistem peringatan dini menjadi tidak berguna. Informasi yang dikirimkan sudah basi dan tidak relevan. Kepercayaan publik terhadap sistem akan hilang. Ini adalah contoh sempurna bagaimana pilihan algoritma yang buruk dapat menggagalkan seluruh proyek teknologi yang kritis.
7. Kesimpulan dan Rekomendasi
Analisis ini membuktikan bahwa kompleksitas algoritma bukanlah sekadar konsep teoretis, melainkan faktor penentu keberhasilan sebuah sistem di dunia nyata.
Kesimpulan:
- Algoritma Iteratif dengan kompleksitas O(n) terbukti sangat efisien, cepat, dan hemat sumber daya. Ini adalah pilihan yang solid dan dapat diandalkan untuk pemrosesan data sekuensial.
- Algoritma Rekursif (naif) dengan kompleksitas O(2n) secara fundamental tidak efisien dan tidak dapat diskalakan. Penggunaannya dalam aplikasi nyata untuk masalah ini adalah sebuah kesalahan desain yang fatal.
Dalam konteks analisis data suhu Jakarta, perbedaan kinerja antara kedua algoritma ini adalah perbedaan antara sistem peringatan dini yang fungsional dan sistem yang gagal total.
Rekomendasi: Untuk tugas-tugas pemrosesan data yang bersifat sekuensial atau akumulatif seperti dalam studi kasus ini, pendekatan iteratif sangat direkomendasikan dan harus menjadi pilihan utama.
Pendekatan rekursif harus dihindari. Meskipun rekursi bisa menjadi alat bantu untuk masalah yang strukturnya memang bercabang (seperti menelusuri struktur direktori file), pengembang harus selalu sadar akan potensi "jebakan" kompleksitas eksponensial. Jika rekursi tetap ingin digunakan untuk masalah seperti ini, ia wajib dioptimalkan dengan teknik memoization (dynamic programming) untuk menyimpan hasil sub-masalah dan menghindari perhitungan berulang. Namun, untuk kasus ini, solusi iteratif tetap lebih sederhana dan lebih efisien secara inheren.
Informasi Course Terkait
Kategori: Algoritma dan PemrogramanCourse: Dasar - Dasar Python



