
Analisis Prediksi Risiko Kanker Paru-Paru
Faiqa Mayesa
Summary
Ini bertujuan untuk memprediksi risiko kanker paru-paru berdasarkan data survei kesehatan yang berisi berbagai faktor seperti usia, kebiasaan merokok, tekanan sosial, tingkat kelelahan, dan kondisi kesehatan lainnya.
Melalui tahapan Exploratory Data Analysis (EDA), dilakukan analisis awal terhadap distribusi data untuk memahami pola dan keseimbangan antar variabel. Setelah itu, data diproses melalui tahap preprocessing yang meliputi pengubahan data kategorikal menjadi numerik, standarisasi fitur, serta pembagian data latih dan data uji.
Model Neural Network kemudian dibangun menggunakan pustaka scikit-learn untuk mengenali pola hubungan antara variabel input dan variabel target (LUNG_CANCER). Hasil evaluasi menunjukkan bahwa model memiliki tingkat akurasi yang tinggi dan mampu mengklasifikasikan risiko kanker paru dengan baik. Visualisasi hasil berupa confusion matrix memperlihatkan keseimbangan antara prediksi dan data aktual, menandakan bahwa model bekerja secara efektif dalam mendeteksi potensi risiko kanker paru-paru pada responden.
Faiqa Mayesa Rahmah (2410514005)
Description
Analisis ini merupakan analisis prediktif terhadap risiko kanker paru-paru berdasarkan faktor gaya hidup dan kondisi kesehatan seseorang. Dataset yang digunakan berasal dari Kaggle, yaitu Survey Lung Cancer Dataset. Dataset ini berisi 309 responden dengan 16 kolom yang menggambarkan karakteristik kesehatan dan kebiasaan hidup.
Dari seluruh kolom, 15 kolom pertama adalah variabel independen (seperti Gender, Age, Smoking, Yellow Fingers, Anxiety, Peer Pressure, dan lainnya), sedangkan kolom terakhir LUNG_CANCER merupakan variabel dependen (target) yang menunjukkan apakah seseorang berisiko terkena kanker paru-paru (YES) atau tidak (NO).
Tujuan dari analisis ini adalah untuk membangun model prediksi menggunakan Neural Network agar dapat mengenali pola-pola tertentu yang berhubungan dengan kemungkinan seseorang menderita kanker paru-paru berdasarkan data survei.

Load Dataset dan Tampilkan Data surveyLungCancer.csv

Periksa Informasi Data (Info & Missing Values)


Exploratory Data Analysis (EDA)
EDA (Exploratory Data Analysis) itu adalah tahap awal dalam analisis data untuk memahami isi, pola, dan karakteristik data sebelum dibuat model.

Disini dilakukan penghapusan kolom GENDER karena dalam menganalisis risiko terkena kanker paru-paru.

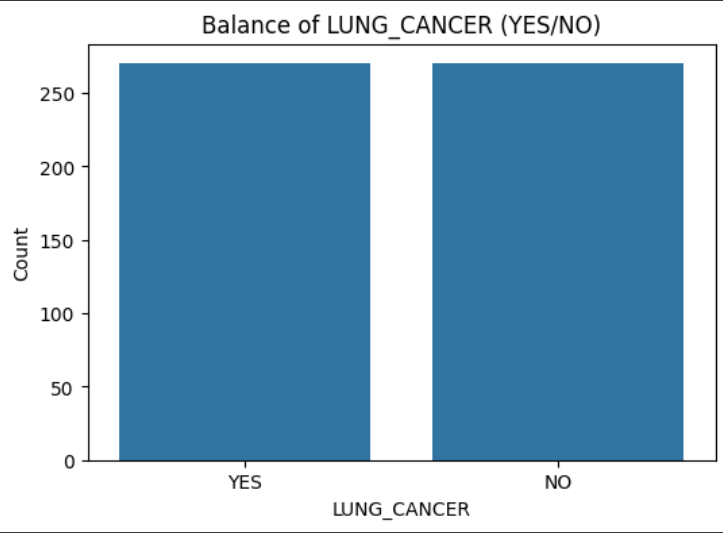
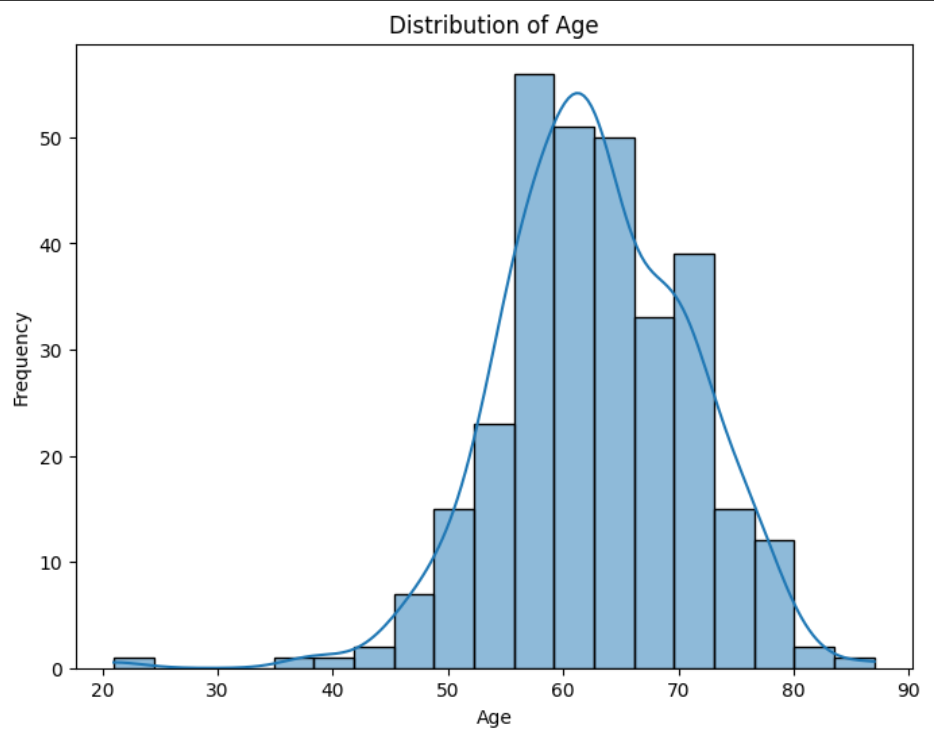
Jadi, EDA digunakan untuk mengenal pola dasar data dulu sebelum lanjut ke tahap selanjutnya. Dengan melihat distribusi usia (AGE) dan perbandingan jumlah kasus LUNG_CANCER (YES/NO), dapat memahami karakteristik responden dan keseimbangan data targetnya. Terlihat dari visualisasi, distribusi usia(AGE) yang terkena kasus paling banyak di umur sekitar lebih dari 55 hingga mendekati umur 60.


Preprocessing
Berikutnya dilakuakan encode categorical features dan scale numeric features.


Pada tahap ini dilakukan encode categorical features. Jadi kalau ada data kategori seperti “YES/NO” pada LUNG_CANCER, harus diubah dulu ke bentuk angka (misalnya 1 dan 0). Proses ini disebut encoding, tujuannya supaya model bisa memahami perbedaan antar kategori secara matematis. Kalau tidak di encode, modeltidak akan bisa memproses data tersebut dengan benar.

Sedangkan pada tahap ini dilakukan scale numeric features karena setiap kolom punya skala nilai yang berbeda. Contohnya, AGE bisa sampai 80, sedangkan SMOKING cuma 0 atau 1. Kalau tidak diseimbangkan, model akan menganggap kolom dengan angka besar lebih penting.
Dengan scaling (StandardScaler), semua fitur disetarakan dalam rentang yang sama, sehingga model bisa belajar secara adil tanpa bias ke salah satu variabel.

Kemudian, disini terdapat split data. Tujuannya biar bisa melatih dan menguji model secara objektif. Data dibagi menjadi dua bagian:
- Data latih (train): untuk mengajarkan pola ke model.
- Data uji (test): untuk melihat seberapa baik model memprediksi data baru yang belum pernah dilihat.
Kalau tidak dilakukan split, model tidak dapat mengenali pola dan hasilnya dapat menipu (kelihatan bagus padahal overfitting).
Build and train a neural network model

Neural Network atau jaringan saraf tiruan adalah metode kecerdasan buatan yang bekerja dengan cara meniru pola berpikir otak manusia. Model ini terdiri dari beberapa lapisan neuron buatan yang saling terhubung dan berfungsi untuk memproses data serta mengenali pola yang kompleks.
Pada tahap ini, model Neural Network dibangun dan dilatih menggunakan pustaka scikit-learn (sklearn). Data latih digunakan agar model dapat mengenali hubungan antara variabel-variabel seperti usia, kebiasaan merokok, tekanan teman sebaya, dan kelelahan terhadap variabel target, yaitu LUNG_CANCER. Setelah proses pelatihan selesai, model diuji menggunakan data uji untuk mengevaluasi seberapa akurat hasil prediksinya terhadap data baru yang belum pernah dilihat sebelumnya.
Hasil pelatihan menunjukkan nilai akurasi sebesar 96,7%, yang menandakan bahwa model mampu melakukan prediksi dengan tingkat ketepatan yang sangat tinggi. Selain itu, ditampilkan pula classification report yang berisi metrik seperti precision, recall, dan f1-score. Nilai metrik yang tinggi pada kelas “1” (positif kanker paru-paru) menunjukkan bahwa model memiliki kemampuan yang baik dalam mengenali individu yang berisiko tinggi. Namun, nilai yang lebih rendah pada kelas “0” menunjukkan adanya ketidakseimbangan data antara kategori pasien yang terkena dan tidak terkena kanker.
Visualisasi


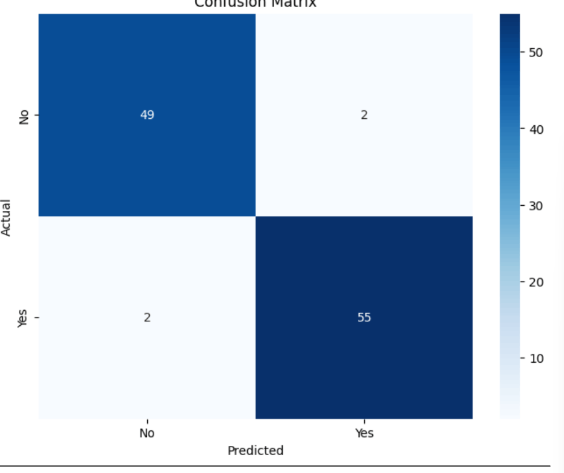
Tahap ini dilakukan untuk mengevaluasi seberapa baik model Neural Network dalam melakukan prediksi serta menampilkan hasilnya secara visual agar lebih mudah dipahami. Salah satu metode yang digunakan adalah Confusion Matrix, yaitu tabel yang menunjukkan perbandingan antara hasil prediksi model dengan data sebenarnya (aktual).
Pada gambar tersebut, sumbu vertikal (Actual) menunjukkan kondisi sebenarnya, sedangkan sumbu horizontal (Predicted) menunjukkan hasil prediksi dari model. Nilai di dalam kotak menggambarkan jumlah data pada masing-masing kategori:
- Kotak kiri atas (49) → jumlah data yang sebenarnya “No” dan diprediksi “No” oleh model (True Negative).
- Kotak kanan bawah (55) → jumlah data yang sebenarnya “Yes” dan diprediksi “Yes” (True Positive).
- Kotak kanan atas (2) → data yang sebenarnya “No”, tetapi diprediksi “Yes” (False Positive).
- Kotak kiri bawah (2) → data yang sebenarnya “Yes”, tetapi diprediksi “No” (False Negative).
Dari hasil tersebut dapat dilihat bahwa model memiliki tingkat kesalahan yang sangat rendah, karena hanya terdapat empat kesalahan prediksi dari total seluruh data uji. Mayoritas data berhasil diprediksi dengan benar oleh model.
Secara keseluruhan, visualisasi confusion matrix ini membuktikan bahwa model Neural Network memiliki performa yang sangat baik dalam mengklasifikasikan apakah seseorang berisiko terkena kanker paru-paru atau tidak. Warna biru tua yang dominan pada diagonal utama (bagian kiri atas dan kanan bawah) menandakan bahwa sebagian besar prediksi model sudah sesuai dengan kondisi sebenarnya.
Informasi Course Terkait
Kategori: Data Science / Big DataCourse: Data Science Tanpa Koding



