
Predictive Analysis on Pima Indians Diabetes
Dahayu Annisa Nathania


Summary
Membuat program Predictive Analysis pada Dataset Pima Indians Diabetes yang bersumber dari Kaggle.com. Program ini bertujuan untuk memprediksi kemungkinan seseorang menderita diabetes berdasarkan berbagai parameter kesehatan seperti kadar glukosa, tekanan darah, usia, dan indeks massa tubuh. Proses analisis dilakukan melalui tahapan Exploratory Data Analysis (EDA) untuk memahami karakteristik data, Data Preprocessing untuk memastikan data siap digunakan, serta Modeling menggunakan algoritma Neural Network (MLPClassifier).
Dari hasil evaluasi model, diperoleh tingkat akurasi sebesar 70%, yang menunjukkan bahwa model memiliki kemampuan cukup baik dalam membedakan pasien dengan dan tanpa diabetes. Visualisasi confusion matrix juga memperlihatkan bahwa model dapat mengklasifikasikan sebagian besar data dengan benar antara kelas “Diabetes” dan “No Diabetes”. Secara keseluruhan, hasil ini menunjukkan bahwa pendekatan Neural Network dapat digunakan sebagai dasar pengembangan sistem prediksi diabetes yang lebih akurat dengan optimasi lanjutan pada parameter dan data pelatihan.
Description
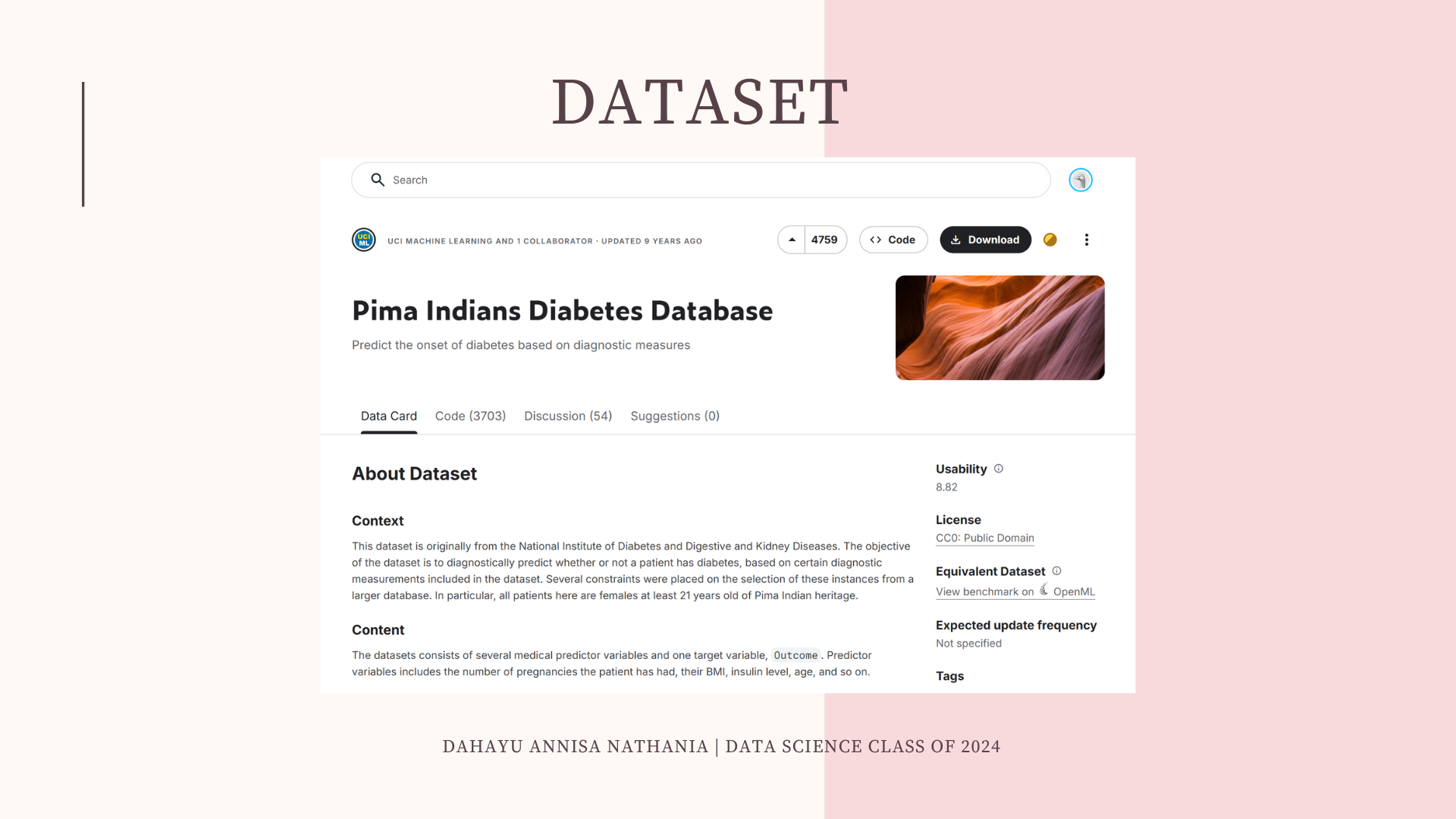
Program “Predictive Analysis on Pima Indian Diabetes” bertujuan untuk menganalisis dan memprediksi kemungkinan seseorang menderita diabetes berdasarkan data medis yang tersedia. Program ini menggunakan dataset Pima Indians Diabetes yang diambil dari Kaggle.com, yang berisi 768 data pasien perempuan keturunan Pima Indian dengan 8 variabel medis seperti Pregnancies, Glucose, Blood Pressure, Skin Thickness, Insulin, BMI, DiabetesPedigreeFunction, dan Age, serta 1 kolom target yaitu Outcome. Melalui dataset ini, program membangun model prediksi menggunakan algoritma MLPClassifier untuk mengklasifikasikan apakah seseorang berisiko terkena diabetes atau tidak. Tujuan akhirnya adalah membantu memahami pola dari data kesehatan dan mendukung proses deteksi dini diabetes secara lebih efisien berbasis data.

Step - Step Program
Read Dataset: Pima Indians Diabetes Database
Fungsi membaca dataset ialah membaca data dari format file yang berbeda (misalnya, CSV, Excel, teks) ke dalam struktur data yang dapat dimanipulasi oleh program.

Pada tahap ini dilakukan proses pembacaan dataset menggunakan library pandas untuk memuat data Pima Indians Diabetes ke dalam bentuk DataFrame. Perintah pd.read_csv() digunakan untuk membaca file diabetes.csv, sedangkan df.head() menampilkan lima baris pertama sebagai sampel untuk memastikan data berhasil diimpor dengan benar. Dari hasil tampilan awal terlihat bahwa dataset berisi beberapa atribut penting seperti Pregnancies, Glucose, BloodPressure, SkinThickness, Insulin, BMI, DiabetesPedigreeFunction, Age, dan Outcome yang nantinya akan digunakan untuk analisis lanjutan dan siap dieksplorasi lebih lanjut pada proses Exploratory Data Analysis (EDA).
Exploratory Data Analysis
Proses ini membantu mengidentifikasi potensi masalah, seperti data yang hilang atau nilai yang tidak valid, sehingga data dapat dibersihkan dan dipersiapkan dengan lebih baik untuk analisis atau machine learning.

Pada tahap ini dilakukan pengecekan keberadaan file diabetes.csv menggunakan modul os untuk memastikan file tersimpan di direktori yang benar. Setelah itu, dataset dibaca menggunakan pandas dan ditampilkan dengan df.head() untuk melihat lima baris pertama data. Dari hasil tampilan terlihat bahwa data berhasil dimuat dengan benar dan berisi beberapa atribut medis penting seperti Glucose, BMI, Age, dan Outcome.

Bagian ini menampilkan hasil dari perintah df.info() yang digunakan untuk melihat struktur dataset secara keseluruhan. Terlihat bahwa dataset memiliki 768 baris dan 9 kolom, seluruhnya bertipe numerik, serta tidak terdapat nilai kosong. Informasi ini menunjukkan bahwa data sudah bersih dan siap diproses lebih lanjut tanpa perlu penanganan missing values.

Tahapan ini digunakan untuk memastikan lokasi penyimpanan dataset di sistem menggunakan perintah os.getcwd() atau sejenisnya. Dari hasil output, file diabetes.csv dipastikan berada di direktori /content, sehingga proses pemanggilan dataset dapat berjalan tanpa error.

Bagian ini menampilkan hasil df.shape[1] untuk mengetahui jumlah kolom dalam dataset. Output menunjukkan bahwa dataset memiliki 9 atribut, yang masing-masing mewakili variabel penting seperti tekanan darah, kadar glukosa, dan status diabetes pasien.

Langkah ini menggunakan fungsi isnull().sum() untuk mengecek apakah terdapat data yang hilang pada setiap kolom. Hasilnya menunjukkan semua kolom bernilai nol, yang berarti tidak ada missing values. Hal ini menandakan dataset sudah bersih dan tidak memerlukan proses imputasi data.

Pada tahap ini dibuat grafik batang menggunakan Matplotlib untuk memperlihatkan distribusi kelas pada kolom Outcome. Hasil visualisasi menunjukkan bahwa jumlah pasien tanpa diabetes (0) lebih banyak dibandingkan dengan pasien yang terdiagnosis diabetes (1). Informasi ini penting untuk memahami kondisi ketidakseimbangan kelas yang dapat memengaruhi performa model saat proses pelatihan.
Data Preprocessing
Fungsi Data Preprocessing yaitu untuk mengubah data mentah menjadi bentuk yang lebih sesuai dengan algoritma data mining yang akan digunakan seperti normalisasi atau standarisasi.

Pada tahap awal preprocessing, dilakukan pengecekan terhadap nilai kosong (missing values) menggunakan fungsi isnull().sum(). Hasil output menunjukkan bahwa seluruh kolom memiliki nilai 0, artinya tidak ada data yang hilang pada dataset. Dengan demikian, tahap penanganan missing values dapat dilewati karena data sudah bersih dan lengkap. Langkah ini penting untuk memastikan kualitas dataset sebelum dilanjutkan ke proses feature scaling dan data splitting.

Pada tahap ini dilakukan proses feature scaling menggunakan metode StandardScaler dari pustaka sklearn.preprocessing. Seluruh kolom numerik selain Outcome dipilih untuk dinormalisasi agar memiliki skala yang seimbang. Proses ini penting agar fitur dengan rentang nilai besar (seperti Insulin atau Glucose) tidak mendominasi model dibandingkan fitur lain. Setelah dilakukan scaling, nilai setiap fitur berubah menjadi rata-rata mendekati 0 dan standar deviasi sekitar 1. Hasil df.head() memperlihatkan data yang sudah terstandarisasi, menandakan proses transformasi berhasil dilakukan dengan baik dan dataset siap digunakan untuk pelatihan model.

Pada bagian ini dilakukan pengecekan terhadap kemungkinan adanya fitur kategorikal menggunakan fungsi select_dtypes(). Hasil output menunjukkan bahwa tidak terdapat kolom bertipe kategorikal dalam dataset, sehingga tahap encoding tidak diperlukan. Langkah ini tetap dilakukan sebagai bagian dari prosedur standar preprocessing untuk memastikan semua fitur telah memiliki format numerik yang sesuai dengan kebutuhan algoritma machine learning.

Pada tahap ini dataset dibagi menjadi dua bagian menggunakan fungsi train_test_split() dari pustaka scikit-learn. Fitur independen (X) dipisahkan dari label target (y), kemudian data dibagi dengan proporsi 75% untuk data latih dan 25% untuk data uji, menggunakan random_state=42 agar hasil pembagian konsisten. Output menunjukkan bahwa data latih terdiri dari 576 baris dan data uji 192 baris. Proses ini penting agar model dapat dilatih pada sebagian data dan dievaluasi pada data yang belum pernah dilihat sebelumnya, sehingga performanya lebih objektif dan terukur.

Dari hasil proses data preprocessing yang dilakukan, diperoleh beberapa temuan penting. Pertama, dataset tidak mengandung missing values, sehingga tidak diperlukan proses imputasi atau penghapusan data. Kedua, seluruh fitur numerik berhasil distandarisasi menggunakan StandardScaler, sehingga setiap variabel memiliki skala yang seimbang. Ketiga, tidak ditemukan fitur kategorikal, sehingga tahap encoding tidak perlu dilakukan. Selanjutnya, data dibagi menjadi data latih (75%) dan data uji (25%), dengan bentuk akhir:
- X_train: (576, 8)
- X_test: (192, 8)
- y_train: (576,)
- y_test: (192,)
Secara keseluruhan, dataset kini sudah siap digunakan untuk tahap pelatihan model machine learning. Karena tidak ada variabel kategorikal, proses preprocessing menjadi lebih sederhana dan efisien tanpa perlu langkah tambahan seperti one-hot encoding.
Training Model
Fungsi dari training model (pelatihan model) adalah untuk melatih algoritma agar dapat mengenali pola, hubungan, dan struktur dari data yang diberikan, sehingga model tersebut mampu membuat prediksi atau keputusan yang akurat di masa depan.

Pada tahap ini dilakukan pelatihan model menggunakan algoritma Multi-Layer Perceptron (MLPClassifier) dari pustaka scikit-learn. Model diinisialisasi dengan satu lapisan tersembunyi berisi 100 neuron (hidden_layer_sizes=(100,)) dan batas iterasi maksimum sebanyak 500 (max_iter=500). Setelah dilakukan pelatihan menggunakan data latih (X_train, y_train), model berhasil terbentuk dengan pesan “MLPClassifier model trained successfully”.
Namun, muncul ConvergenceWarning, yang menandakan bahwa proses optimisasi belum sepenuhnya konvergen dalam 500 iterasi. Hal ini umum terjadi pada jaringan saraf ketika jumlah iterasi terlalu rendah atau parameter belum optimal. Meski begitu, model tetap dapat digunakan, namun peningkatan nilai max_iter atau penyesuaian parameter lainnya dapat membantu mencapai hasil pelatihan yang lebih stabil dan akurat di tahap berikutnya.

Kemudian, dilakukan pelatihan ulang model MLPClassifier dengan peningkatan jumlah iterasi maksimum dari 500 menjadi 1000 untuk membantu proses konvergensi. Meskipun model berhasil dilatih dan menghasilkan pesan “MLPClassifier model trained successfully”, peringatan ConvergenceWarning masih muncul. Hal ini menunjukkan bahwa algoritma belum mencapai titik stabil (optimal weights) meskipun iterasi telah ditingkatkan.
Situasi seperti ini umum terjadi pada model jaringan saraf karena sensitivitasnya terhadap parameter pelatihan. Untuk meningkatkan performa, langkah selanjutnya dapat mencakup penyesuaian hyperparameter lain seperti solver (misalnya 'adam' atau 'lbfgs'), nilai regularisasi alpha, atau tingkat pembelajaran learning_rate_init. Meskipun begitu, model yang dihasilkan saat ini tetap dapat digunakan untuk evaluasi awal terhadap performa klasifikasi.

Pada tahap ini, model MLPClassifier yang telah dilatih digunakan untuk melakukan prediksi terhadap data uji (X_test) menggunakan perintah mlp.predict(). Hasil prediksi disimpan dalam variabel y_pred, yang berisi label kelas yang diperkirakan oleh model. Output menunjukkan bahwa proses prediksi berhasil dilakukan tanpa error, ditandai dengan pesan “Predictions on the test set have been made.”
Langkah ini menjadi dasar untuk tahap berikutnya, yaitu evaluasi performa model melalui metrik seperti accuracy, precision, recall, dan F1-score, guna menilai seberapa baik model dalam mengklasifikasikan data baru berdasarkan hasil pelatihannya.

Pada tahap evaluasi ini, performa model MLPClassifier diuji menggunakan beberapa metrik utama, yaitu accuracy, precision, recall, dan F1-score. Berdasarkan hasil perhitungan, model memperoleh accuracy sebesar 0.7083 atau sekitar 70.8%, dengan nilai precision, recall, dan F1-score masing-masing sebesar 0.5942.
Nilai akurasi menunjukkan bahwa model mampu memprediksi dengan benar sekitar 71% dari seluruh data uji. Sementara itu, kesetaraan antara nilai precision dan recall mengindikasikan bahwa model memiliki keseimbangan dalam mengenali kasus positif, meskipun performanya masih dapat ditingkatkan. Secara keseluruhan, hasil ini menunjukkan bahwa model sudah cukup baik untuk tahap awal, namun masih berpotensi ditingkatkan melalui penyesuaian hyperparameter atau teknik optimisasi tambahan.

Bagian visualize evaluation bertujuan untuk menampilkan performa model secara lebih intuitif melalui representasi visual. Pada tahap ini, digunakan confusion matrix sebagai alat untuk memetakan hasil prediksi model terhadap data uji. Melalui kode yang memanfaatkan fungsi confusion_matrix dari pustaka sklearn.metrics serta visualisasi menggunakan seaborn.heatmap, distribusi antara prediksi benar dan salah dapat diamati dengan jelas. Visualisasi ini menampilkan dua kelas utama, yaitu “No Diabetes (0)” dan “Diabetes (1)”, dengan nilai pada diagonal matriks merepresentasikan jumlah prediksi yang sesuai dengan label sebenarnya.
Evaluation
Dalam analisis prediktif, evaluasi berfungsi untuk mengukur seberapa dekat prediksi model dengan hasil aktual.

Dari hasil visualisasi, tampak bahwa model memiliki performa yang cukup baik karena sebagian besar data berada pada posisi diagonal pada Confusion Matrix, yang menandakan banyaknya prediksi yang tepat. Sementara itu, nilai di luar diagonal menunjukkan area di mana model masih melakukan kesalahan klasifikasi. Secara lebih spesifik, model berhasil memprediksi 95 pasien non-diabetes dengan benar dan 41 pasien diabetes secara akurat, namun masih terdapat 28 kasus salah klasifikasi di mana pasien non-diabetes diprediksi sebagai diabetes.
Visualisasi ini memberikan gambaran intuitif mengenai kekuatan dan kelemahan model, serta memperlihatkan apakah model lebih unggul dalam mendeteksi kasus positif atau negatif. Dengan demikian, performa model tidak hanya dapat dievaluasi melalui angka akurasi, tetapi juga melalui pemahaman yang lebih mendalam mengenai pola kesalahan prediksi. Tahap ini menjadi dasar penting dalam menentukan langkah fine-tuning atau penyeimbangan data agar akurasi model dapat meningkat secara keseluruhan.
Informasi Course Terkait
Kategori: Data Science / Big DataCourse: Cloud Computing



