
Deep Learning Dengan Keras Python
Risqa Ciety Windari



Summary
Keras adalah pustaka Python tingkat tinggi yang dirancang untuk memudahkan pengembangan dan pelatihan model deep learning. Keras beroperasi di atas backend komputasi seperti TensorFlow, Theano, atau CNTK, menyediakan antarmuka yang ramah pengguna untuk membangun jaringan saraf. Dengan Keras, pengguna dapat dengan cepat membuat dan bereksperimen dengan berbagai arsitektur deep learning tanpa perlu berurusan dengan detail tingkat rendah dari backend.
Description
📦 1. Pilih Dataset dari Kaggle
Contoh dataset:
"Iris Dataset":
https://www.kaggle.com/datasets/arshid/iris-flower-dataset
File: Iris.csv
💡 2. Siapkan Google Colab (atau Jupyter Notebook)
Gunakan Google Colab karena bisa langsung konek ke Kaggle dan tidak perlu install lokal.
🔑 3. Akses Dataset dari Kaggle
Langkah:
Kunjungi: https://www.kaggle.com → klik foto profil → "Account"
Scroll ke bawah → klik "Create New API Token"
Akan terunduh file: kaggle.json
from tensorflow import keras
from tensorflow.keras.layers import Dense, Flatten
from tensorflow.keras.datasets import mnist
from tensorflow.keras.utils import to_categorical
# Muat data MNIST
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# Preproses data
x_train = x_train.reshape(60000, 784).astype('float32') / 255
x_test = x_test.reshape(10000, 784).astype('float32') / 255
y_train = to_categorical(y_train, num_classes=10)
y_test = to_categorical(y_test, num_classes=10)
# Definisikan model
model = keras.Sequential([
Flatten(input_shape=(784,)),
Dense(128, activation='relu'),
Dense(10, activation='softmax')
])
# Kompilasi model
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
# Latih model
model.fit(x_train, y_train, epochs=2, batch_size=32)
# Evaluasi model
loss, accuracy = model.evaluate(x_test, y_test)
print('Loss:', loss)
print('Accuracy:', accuracy)
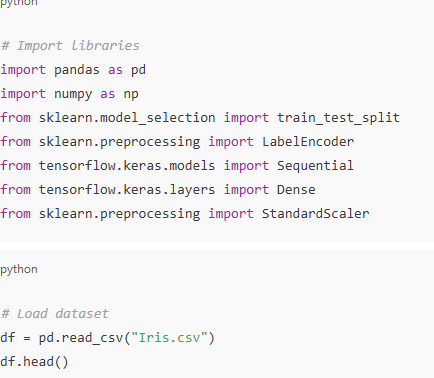
# Import libraries import pandas as pd import numpy as np from sklearn.model_selection import train_test_split from sklearn.preprocessing import LabelEncoder from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Dense from sklearn.preprocessing import StandardScaler
# Load dataset df = pd.read_csv("Iris.csv") df.head()
# Drop kolom yang tidak perlu df.drop(['Id'], axis=1, inplace=True) # Pisahkan fitur dan label X = df.drop('Species', axis=1) y = df['Species'] # Encode label le = LabelEncoder() y_encoded = le.fit_transform(y) # Normalisasi fitur scaler = StandardScaler() X_scaled = scaler.fit_transform(X) # Split data X_train, X_test, y_train, y_test = train_test_split(X_scaled, y_encoded, test_size=0.2, random_state=
model = Sequential()
model.add(Dense(8, input_shape=(4,), activation='relu'))
model.add(Dense(6, activation='relu'))
model.add(Dense(3, activation='softmax')) # 3 kelas (Iris-setosa, versicolor, virginica)
# Compile model
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
import matplotlib.pyplot as plt
# Akurasi
plt.plot(history.history['accuracy'], label='Training Accuracy')
plt.plot(history.history['val_accuracy'], label='Validation Accuracy')
plt.title('Model Accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.legend()
plt.show()
# Loss
plt.plot(history.history['loss'], label='Training Loss')
plt.plot(history.history['val_loss'], label='Validation Loss')
plt.title('Model Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
plt.show()
history = model.fit(X_train, y_train, epochs=100, batch_size=5, verbose=1, validation_split=0.2)
loss, accuracy = model.evaluate(X_test, y_test, verbose=0)
print(f"Test Accuracy: {accuracy*100:.2f}%")
Informasi Course Terkait
Kategori: Algoritma dan PemrogramanCourse: Basic Cybersecurity 10-12



