
Analisis & Deteksi Transaksi Kartu Kredit
Nurmalia Indriyani Putri


Summary
Proyek ini bertujuan untuk mendeteksi transaksi kartu kredit yang mencurigakan menggunakan pendekatan Business Intelligence, dimulai dari Exploratory Data Analysis (EDA) hingga pembangunan model prediktif berbasis machine learning. Dataset yang digunakan merupakan data transaksi kartu kredit di Eropa, yang bersifat sangat tidak seimbang karena jumlah transaksi fraud jauh lebih sedikit dibanding non-fraud. Melalui EDA, diperoleh pemahaman pola distribusi waktu, nilai transaksi, dan korelasi antar fitur. Fitur penting dipilih berdasarkan analisis korelasi terhadap variabel target Class. Data kemudian diproses melalui normalisasi dan penyeimbangan dengan SMOTE, dan model Linear Regression digunakan sebagai algoritma prediktif, dikonversi menjadi klasifikasi biner. Hasil evaluasi menunjukkan performa yang sangat baik, dengan akurasi 93%, precision untuk fraud 97%, dan ROC AUC Score 0.9657. Hasil ini membuktikan bahwa analisis data terstruktur dan penerapan machine learning mampu memberikan insight yang akurat dan bermanfaat dalam sistem deteksi fraud, serta mendukung pengambilan keputusan berbasis data untuk meningkatkan keamanan transaksi digital.
Description

Latar Belakang
Peningkatan jumlah transaksi digital menyebabkan tingginya risiko penyalahgunaan kartu kredit. Data besar yang dihasilkan dari aktivitas ini perlu dianalisis untuk mendeteksi pola yang tidak wajar. Dengan pendekatan Business Intelligence, perusahaan dapat mengolah data historis transaksi untuk mengambil keputusan berbasis data, termasuk deteksi fraud secara dini.
Tujuan
- Mengetahui pola dan distribusi transaksi kartu kredit melalui EDA
- Mengidentifikasi variabel-variabel yang mempengaruhi potensi fraud
- Membangun model prediksi untuk mendeteksi transaksi mencurigakan menggunakan algoritma machine learning
- Memberikan insight yang dapat membantu pengambilan keputusan dan peningkatan sistem keamanan
Deskripsi Dataset
Dataset creditcard.csv berisi data transaksi kartu kredit yang dilakukan oleh nasabah di Eropa selama dua hari pada bulan September 2013. Tujuan utamanya adalah untuk mendeteksi transaksi penipuan (fraud detection) menggunakan metode analisis data dan machine learning.
Tools Yang Digunakan

Dalam proyek ini, digunakan Google Colab sebagai platform utama untuk analisis data, visualisasi, dan pembuatan model machine learning. Google Spreadsheet dimanfaatkan untuk melihat dan mencatat data secara tabular, sementara Google Drive berfungsi sebagai tempat penyimpanan dataset dan notebook.
Exploratory Data Analysis (EDA)
1. Preprocessing Data


Tujuan utama melakukan preprocessing data adalah untuk meningkatkan kualitas data dan menyiapkannya agar sesuai untuk analisis atau pemodelan machine learning. SMOTE berhasil menyeimbangkan distribusi kelas, menghasilkan 283.253 sampel untuk Class 0 dan Class 1 masing-masing. Dataset kemudian dibagi menjadi data latih (396.554 sampel) dan data uji (169.952 sampel)
Catatan:
SMOTE (Synthetic Minority Over-sampling Technique) adalah algoritma over-sampling yang digunakan dalam machine learning untuk mengatasi masalah ketidakseimbangan kelas (imbalanced classes) dalam dataset. Ketidakseimbangan kelas terjadi ketika jumlah sampel dari satu kelas (kelas mayoritas) jauh lebih banyak daripada jumlah sampel dari kelas lain (kelas minoritas).
2. Visualisasi Data
a. Analisis Distribusi Kelas Target (Fraud vs Non-Fraud)

Grafik yang ditampilkan menunjukkan distribusi kelas pada data transaksi, khususnya membandingkan antara transaksi yang tergolong non-fraud (tidak penipuan) dengan transaksi yang tergolong fraud (penipuan).
Interpretasi Grafik:
Sumbu X (Class): Mewakili dua kategori data:
0: Transaksi non-fraud atau normal
1: Transaksi fraud atau penipuan
Sumbu Y (Count): Menunjukkan jumlah transaksi dalam masing-masing kategori.
Terlihat bahwa jumlah transaksi dengan label 0 (non-fraud) sangat tinggi, sekitar 270.000+ transaksi, sementara transaksi dengan label 1 (fraud) hampir tidak terlihat di grafik karena jumlahnya sangat kecil, kemungkinan hanya ratusan atau kurang dari 1% dari total data.
b. Visualisasi Distribusi Fitur Numerik

Berdasarkan grafik, mayoritas nilai transaksi berada di bawah 500, dengan jumlah mencapai lebih dari 1,4 juta transaksi. Sementara itu, nilai transaksi di atas 5000 sangat jarang terjadi. Bahkan, transaksi bernilai ekstrem hingga 25.000 hampir tidak terlihat karena jumlahnya sangat kecil. Hal ini menunjukkan bahwa data sangat tidak seimbang, dengan konsentrasi tinggi pada transaksi bernilai rendah.
c. Visualisasi Distribusi Fitur Waktu

Gambar tersebut menunjukkan distribusi waktu transaksi dalam bentuk histogram, dengan sumbu X mewakili waktu dalam satuan detik sejak awal pencatatan, dan sumbu Y menunjukkan jumlah transaksi yang terjadi. Terlihat bahwa distribusi ini memiliki dua puncak utama, yaitu sekitar detik ke-75.000 dan detik ke-150.000, yang mengindikasikan bahwa transaksi paling banyak terjadi pada dua rentang waktu tertentu, kemungkinan pada siang hingga malam hari. Di antara dua puncak tersebut terdapat penurunan tajam, yang kemungkinan mencerminkan waktu malam atau dini hari saat aktivitas transaksi menurun.
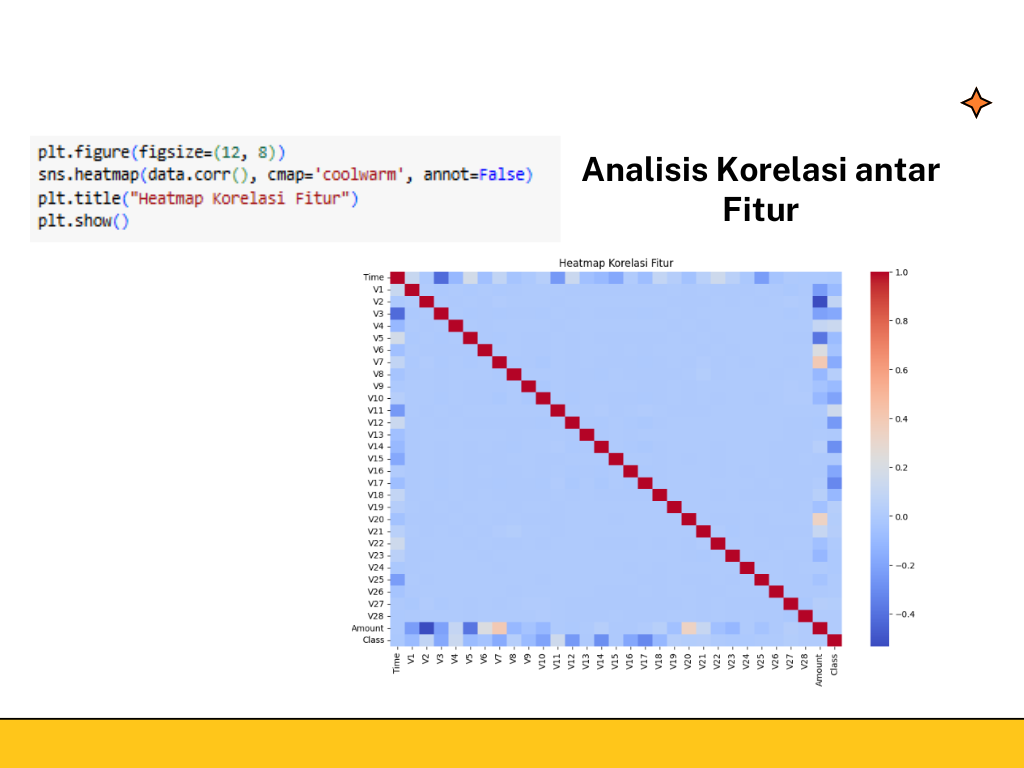
d. Analisis Korelasi Antar Fitur

Menunjukkan "Heatmap Korelasi Fitur" yang menampilkan matriks korelasi antara berbagai fitur dalam sebuah dataset, termasuk "Time", "V1" hingga "V28", "Amount", dan "Class". Warna pada heatmap menunjukkan kekuatan dan arah korelasi: warna merah mengindikasikan korelasi positif yang kuat (mendekati 1), warna biru mengindikasikan korelasi negatif yang kuat (mendekati -1), dan warna putih/abu-abu menunjukkan korelasi yang lemah atau tidak ada (mendekati 0).
e. Transaksi Fraud vs Non-Fraud

Grafik boxplot transaksi non-fraud (Class 0) maupun transaksi fraud (Class 1) didominasi oleh nilai-nilai yang sangat rendah, terlihat dari rentang interkuartil (kotak) yang pendek dan dekat dengan nol pada kedua kelas. Namun, terdapat perbedaan signifikan pada sebaran nilai yang lebih tinggi: Class 0 menunjukkan banyak outlier atau transaksi non-fraud dengan nilai yang jauh lebih besar, sementara transaksi fraud (Class 1) memiliki nilai maksimum (outlier) yang tampak jauh lebih rendah.
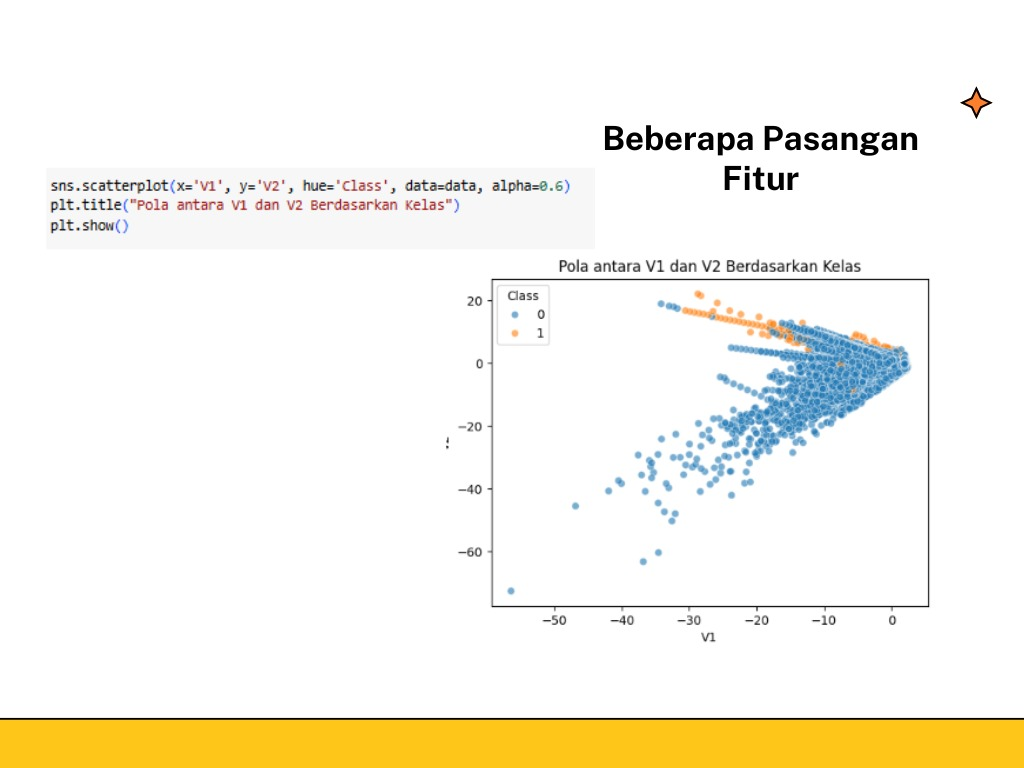
f. Beberapa Pasangan Fitur
Mengambil contoh V1 dan V2 divisualisasikan dengan scatterplot

Distribusi Class 0 (biru) dan Class 1 (oranye) menunjukkan overlapping yang signifikan, khususnya di area V1 antara -10 hingga 0 dan V2 antara 0 hingga 20. Class 1 cenderung terkonsentrasi di bagian atas grafik dengan nilai V2 positif, sementara Class 0 lebih tersebar luas, menempati nilai V2 negatif dan V1 yang lebih negatif.
Model Prediktif


Confusion Matrix:
- [[82769 2207]]: Ini menunjukkan hasil untuk Class 0 (negatif). Ada 82.769 kasus yang benar diklasifikasikan sebagai Class 0 (True Negatives) dan 2.207 kasus Class 0 yang salah diklasifikasikan sebagai Class 1 (False Positives).
- [[10110 74866]]: Ini menunjukkan hasil untuk Class 1 (positif). Ada 10.110 kasus Class 1 yang salah diklasifikasikan sebagai Class 0 (False Negatives) dan 74.866 kasus yang benar diklasifikasikan sebagai Class 1 (True Positives).
Classification Report: Laporan ini memberikan metrik kinerja untuk setiap kelas (0 dan 1) dan juga rata-rata keseluruhan.
- Class 0 (Non-Fraud/Negatif):
- Precision: 0.89. Ini berarti dari semua kasus yang diprediksi sebagai Class 0, 89% di antaranya benar-benar Class 0.
- Recall: 0.97. Ini berarti model berhasil mengidentifikasi 97% dari semua kasus Class 0 yang sebenarnya.
- F1-score: 0.93. F1-score adalah rata-rata harmonik dari precision dan recall, memberikan keseimbangan antara keduanya.
- Support: 84976. Ini adalah jumlah aktual kasus Class 0 dalam dataset.
- Class 1 (Fraud/Positif):
- Precision: 0.97. Ini berarti dari semua kasus yang diprediksi sebagai Class 1, 97% di antaranya benar-benar Class 1.
- Recall: 0.88. Ini berarti model berhasil mengidentifikasi 88% dari semua kasus Class 1 yang sebenarnya.
- F1-score: 0.92.
- Support: 84976. Ini adalah jumlah aktual kasus Class 1 dalam dataset.
Rata-rata Keseluruhan:
- Accuracy: 0.93. Akurasi keseluruhan model adalah 93%.
- Macro avg: Precision, recall, dan f1-score rata-rata untuk kedua kelas dihitung tanpa mempertimbangkan ketidakseimbangan jumlah sampel. Nilainya adalah 0.93 untuk ketiganya.
- Weighted avg: Precision, recall, dan f1-score rata-rata untuk kedua kelas dihitung dengan mempertimbangkan jumlah sampel (support) masing-masing kelas. Nilainya juga 0.93 untuk ketiganya.
- Total Support: 169952 (84976 + 84976).
ROC AUC Score:
- ROC AUC Score: 0.9657231799747744. Ini adalah metrik kinerja untuk model klasifikasi biner. Nilai yang mendekati 1 menunjukkan bahwa model memiliki kemampuan yang sangat baik untuk membedakan antara kelas positif dan negatif. Skor 0.9657 menunjukkan kinerja klasifikasi yang sangat kuat.

Semakin dekat kurva ke sudut kiri atas, semakin baik kemampuan model dalam membedakan kelas positif (fraud) dan negatif (non-fraud).
Model menghasilkan AUC (Area Under Curve) sebesar 0.97, yang berarti model sangat andal dan memiliki tingkat prediksi yang sangat baik. Nilai AUC mendekati 1 menunjukkan bahwa model hampir sempurna dalam memisahkan antara transaksi fraud dan non-fraud
Kesimpulan
Melalui tahapan EDA, diperoleh pemahaman awal mengenai struktur data, distribusi kelas (fraud vs non-fraud), dan hubungan antar fitur. Hasil EDA menunjukkan bahwa data bersifat sangat tidak seimbang, dengan jumlah transaksi fraud jauh lebih sedikit dibanding transaksi normal. Selain itu, fitur-fitur dengan korelasi tinggi terhadap target Class berhasil diidentifikasi sebagai fitur penting.
Pada tahap preprocessing, dilakukan normalisasi data, penghapusan duplikasi, dan penyeimbangan data menggunakan metode SMOTE. Setelah itu, model Linear Regression digunakan sebagai metode prediktif, dengan pendekatan threshold untuk mengubah output regresi menjadi klasifikasi fraud atau non-fraud.
Hasil pengujian menunjukkan bahwa model memberikan performa yang sangat baik, dengan akurasi sebesar 93%, precision untuk fraud 97%, dan ROC AUC Score sebesar 0.9657, yang mengindikasikan kemampuan klasifikasi yang sangat kuat.
Informasi Course Terkait
Kategori: Data Science / Big DataCourse: Memahami Fundamental Project Management untuk Berkarir menjadi Seorang Manager Proyek



