
VISUALISASI DATA PENYAKIT JANTUNG
Dwi Rosa indah

Summary
Tugas akhir ini dibuat untuk melihat visualisasi data terhadap Penyakit kardiovaskular (CVD). CVD adalah penyebab kesakitan dan kematian paling umum pada pria dan wanita di seluruh dunia. Diperkirakan 18 juta kematian dilaporkan akibat CVD setiap tahunnya, mewakili hampir sepertiga dari seluruh kematian global. Sebagian besar kematian tersebut (85%) disebabkan oleh serangan jantung dan stroke. Setiap tiga dari empat kematian akibat penyakit CVD terjadi di negara-negara berpendapatan rendah dan menengah. Data digunakan merupakan dataset public dari kaggle.com. Data set mencakup :
- Age: umur dalam tahun.
- Sex: Jenis kelamin (1=laki-laki; 0=perempuan).
- Cp: jenis nyeri dada (0 = angina tipikal; 1 = angina atipikal; 2 = nyeri nonangina; 3: tanpa gejala).
- Trestbps: tekanan darah istirahat dalam mm Hg saat masuk rumah sakit.
- Chol: kolesterol serum dalam mg/dl. fbs: gula darah puasa > 120 mg/dl (1=benar; 0=salah).
- Restecg: hasil elektrokardiografi istirahat ( 0=normal; 1=memiliki kelainan gelombang ST-T; 2=kemungkinan atau pasti hipertrofi ventrikel kiri).
- Thalach: tercapai denyut jantung maksimal.
- Exang: angina akibat olahraga (1=ya; 0=tidak).
- Oldpeak: Depresi ST yang disebabkan oleh olahraga dibandingkan dengan istirahat.
- Slope: kemiringan puncak latihan ruas ST (0=menanjak; 1=datar; 2=turun).
- Ca: jumlah pembuluh darah besar (0–3) yang diwarnai dengan fluorosopy.
- Thal: thalassemia (3=normal; 6=cacat tetap; 7=cacat reversibel).
- Target: penyakit jantung (1=tidak, 2=ya).
Description
Tugas Akhir Sertifikasi DSBIZ
Oleh: Dwi Rosa Indah
Tugas akhir ini dibuat untuk melihat visualisasi data terhadap Penyakit kardiovaskular (CVD). CVD adalah penyebab kesakitan dan kematian paling umum pada pria dan wanita di seluruh dunia. Diperkirakan 18 juta kematian dilaporkan akibat CVD setiap tahunnya, mewakili hampir sepertiga dari seluruh kematian global. Sebagian besar kematian tersebut (85%) disebabkan oleh serangan jantung dan stroke. Setiap tiga dari empat kematian akibat penyakit CVD terjadi di negara-negara berpendapatan rendah dan menengah. Data digunakan merupakan dataset public dari kaggle.com. Data set mencakup :
- Age: umur dalam tahun.
- Sex: Jenis kelamin (1=laki-laki; 0=perempuan).
- Cp: jenis nyeri dada (0 = angina tipikal; 1 = angina atipikal; 2 = nyeri nonangina; 3: tanpa gejala).
- Trestbps: tekanan darah istirahat dalam mm Hg saat masuk rumah sakit.
- Chol: kolesterol serum dalam mg/dl. fbs: gula darah puasa > 120 mg/dl (1=benar; 0=salah).
- Restecg: hasil elektrokardiografi istirahat ( 0=normal; 1=memiliki kelainan gelombang ST-T; 2=kemungkinan atau pasti hipertrofi ventrikel kiri).
- Thalach: tercapai denyut jantung maksimal.
- Exang: angina akibat olahraga (1=ya; 0=tidak).
- Oldpeak: Depresi ST yang disebabkan oleh olahraga dibandingkan dengan istirahat.
- Slope: kemiringan puncak latihan ruas ST (0=menanjak; 1=datar; 2=turun).
- Ca: jumlah pembuluh darah besar (0–3) yang diwarnai dengan fluorosopy.
- Thal: thalassemia (3=normal; 6=cacat tetap; 7=cacat reversibel).
- Target: penyakit jantung (1=tidak, 2=ya).
Tugas akhir ini menampilkan 3 visualisasi data yaitu
- Menampilkan korelasi antar atribut
- Menampilkan diagram pie untuk menampilkan jumlah yang menderita penyakit jantung dan tidak
- Menampilkan grafik distribusi usia yang berpenyakit jantung dan tidak
Sebelum menampilkan visualisasi data, program diawali dengan import library yang akan digunakan dengan kode sebagai berikut:

Library yang digunakan yaitu pandas untuk memproses data, mulai pembersihan data, manipulasi data dan analisis data. Library matplotlib digunakan untuk menciptakan visualisasi data dengan grafis yang menarik dan informatif. Library drive dari google colab digunakan untuk menggunakan data yang tersimpan pada google drive. Library seaborn digunakan untuk menampilkan antarmuka tingkat tinggi untuk menggambar grafik statistik yang menarik dan informatif.
Setelah dilakukan import library maka dilakukan pemanggilan data dari google drive dengan menggunakan kode sebagai berikut:

Langkah selanjutnya adalah membaca file dataset yang berekstensi .csv ke kode program, seperti yang terlihat pada gambar berikut:

Memastikan bahwa tidak ada data yang missing value dengan menggunakan df.info () seperti yang terlihat pada gambar :

Selanjutnya menampilkan statistik deskriptif data untuk mendapatkan gambaran umum singkat tentang kumpulan data seperti jumlah, rata-rata, standar deviasi dari masing-masing atribut seperti age, sex dll, dengan menggunakan perintah describe ()

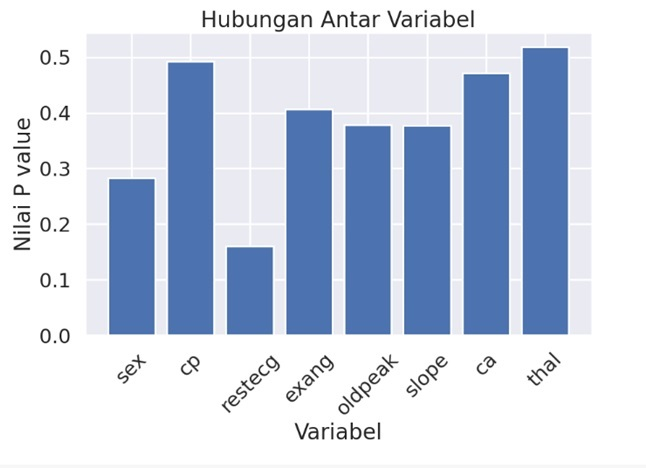
Selanjutnya menampilkan visualisasi nilai korelasi variabel target terhadap variabel lain pada df menggunakan nilai chi square dengan uji p-value, dimana nilai chi-square yang baik < 0.05. Menggunakan chi square karena datanya bukan numerik



Dari hasil grafik diatas didapatkan bahwa variabel yang berkorelasi adalah sex, cp, restecg, exang, oldpeak,ca,thal yang berpengaruh terkena jantung. Dengan menggunakan grafik bar dapat melihat perbedaan nilai P value dari variabel
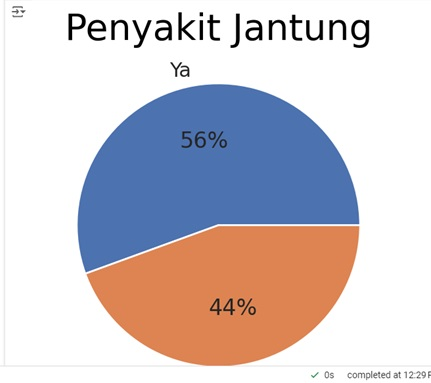
Visualisasi kedua, menampilkan diagram pie untuk menampilkan total persentase dari jumlah yang terkena penyakit jantung dan tidak berdasarkan seluruh data

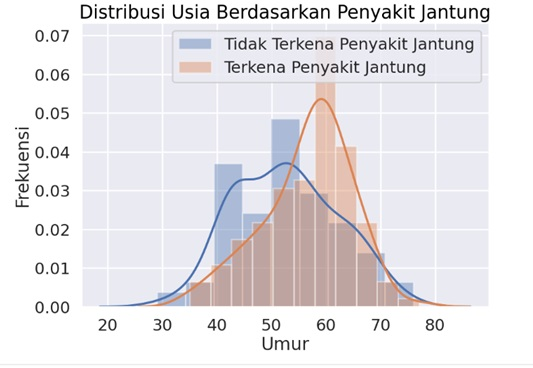
Visualisasi yang ketiga adalah visualisasi grafik distribusi untuk menggambarkan pola penyebaran data dari variabel kontinu seperti umur yang terkena penyakit jantung dan tidak. Berdasarkan grafik tersebut dapat dilihat bahwa rentang usia 60 -65 tahun dengan frekuensi 7% yang paling banyak terkena penyakit jantung sedangkan rentang umur 50 -55 tahun dengan frekuensi 4,9% tidak terkena penyakit jantung. Kode yang digunakan adalah sebagai berikut:


Informasi Course Terkait
Kategori: Data Science / Big DataCourse: Persiapan Ujian Sertifikasi Internasional DSBIZ dan AIBIZ



