
Speech Classification dengan Machine Learning
Senela Avriani Difa

Summary
Speech classification dengan machine learning adalah proses menggunakan algoritma pembelajaran mesin untuk mengklasifikasikan data suara ke dalam kategori tertentu. Proses ini melibatkan berbagai tahap, dari pengumpulan dan pra-pemrosesan data suara hingga pelatihan model dan evaluasi performa.
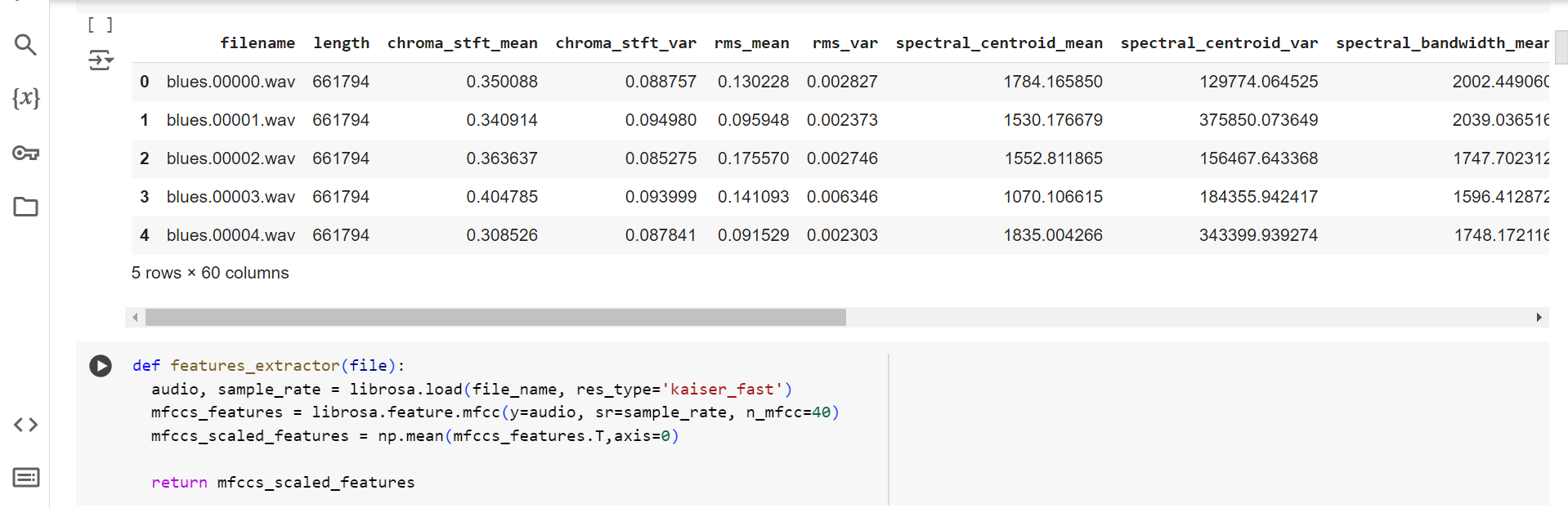
Pada latihan kali ini saya menggunakan dataset berupa daatset suara yang saya dapat dari kaggle.com “genres_original”
Description
1. Tahapan pertama yaitu mengimport library yang akan dibutuhkan untuk program kali ini yaitu terdapat library pandas, numpy, IPython.display, dan sebagainya yang tertera pada gambar di bawah serta menghubungkan gdrive dengan google colab untuk membaca dataset.


2. Tahapan selanjutnya dengan mengekstraksi fitur MFCC dari sekumpulan file audio dan menggabungkannya dengan label yang sesuai, sehingga dapat digunakan sebagai data pelatihan untuk model klasifikasi suara.

3. pd.DataFrame(extracted_features, columns=['feature', 'class']): Membuat DataFrame baru dari list extracted_features.
- extracted_features: List ini berisi elemen-elemen yang masing-masing adalah pasangan dari fitur (data) dan label kelas.
- columns=['feature', 'class']: Menetapkan nama kolom untuk DataFrame tersebut. Kolom pertama dinamakan 'feature' yang berisi fitur-fitur yang diekstraksi (seperti MFCC), dan kolom kedua dinamakan 'class' yang berisi label kelas dari setiap file audio.

4. Program selanjutnya digunakan untuk membagi dataset menjadi set pelatihan (training set) dan set pengujian (test set) menggunakan library scikit-learn


5. Langkah penting untuk memastikan bahwa pembagian dataset telah dilakukan dengan benar dan bahwa dimensi data sesuai dengan yang dibutuhkan. Saya menggunakan model jaringan saraf tiruan (neural network) menggunakan Keras, yang merupakan sebuah high-level API untuk membangun dan melatih model deep learning. Model ini dirancang untuk klasifikasi dengan beberapa lapisan dense (fully connected) dan dropout untuk regularisasi.


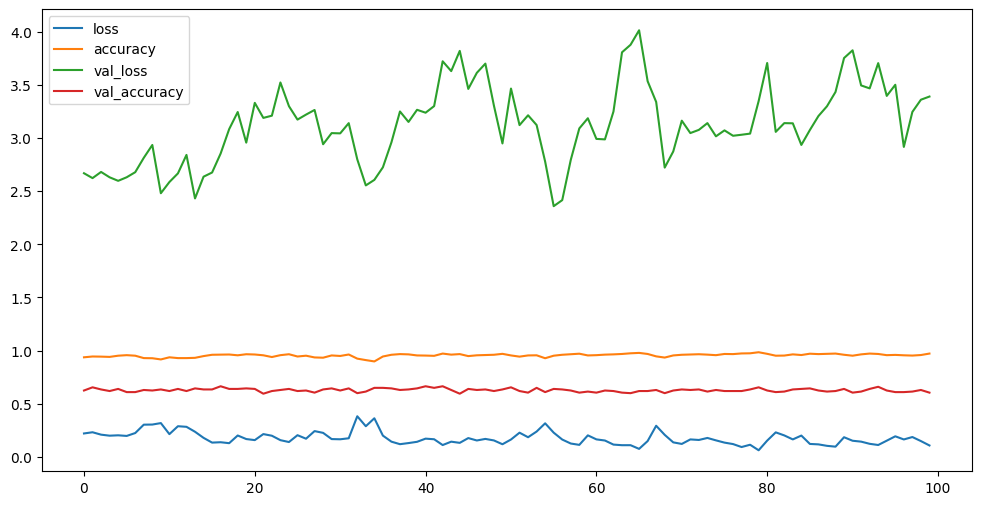
6. Selanjutnya pada training model yaitu untuk melatih model jaringan saraf tiruan (neural network) yang telah didefinisikan sebelumnya. Proses pelatihan ini melibatkan penggunaan callback untuk menyimpan model terbaik dan mencatat durasi pelatihan.

7. Selanjutnya akan menampilkan grafik evaluate


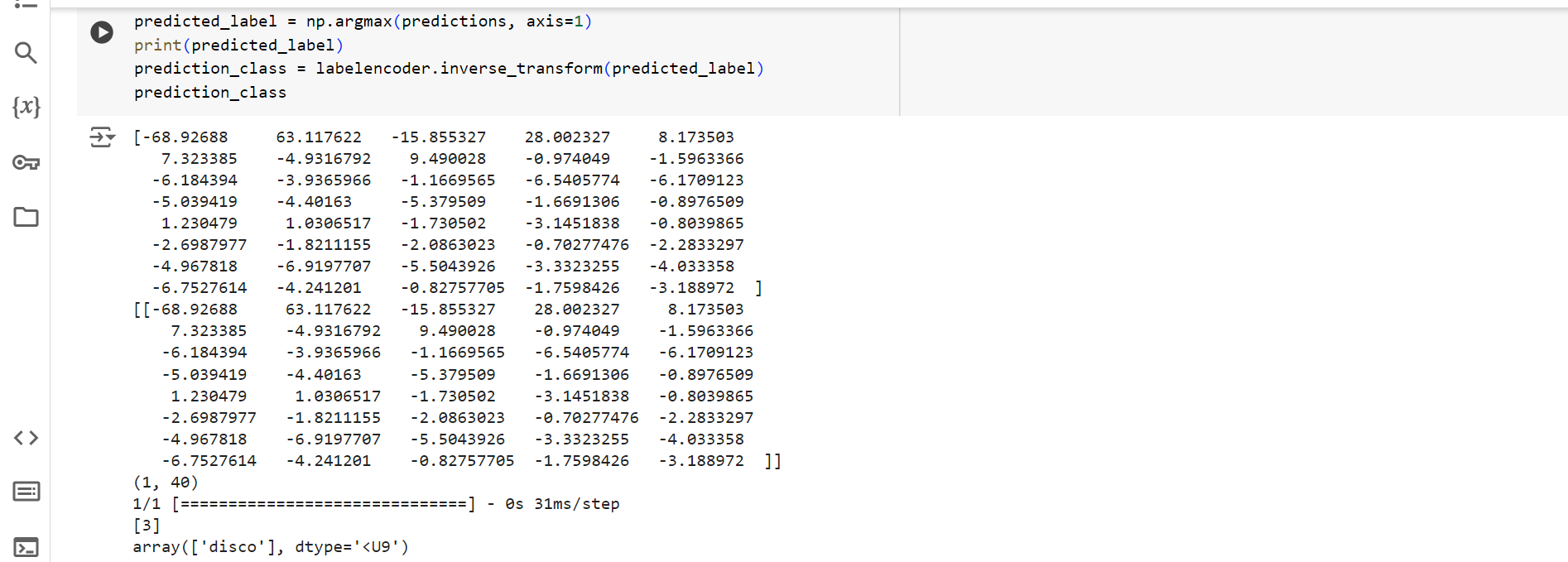
8. Tahapan terakhir yaitu untuk membuat prediksi pada file audio tertentu menggunakan model jaringan saraf tiruan yang telah dilatih. bermula dari emmbuat prediksi sampai mengoversi label prediksi ke nama kelas. Pada percobaan kali ini saya mencoba copy path salah satu data dan ketika di run akan memunculkan data yang sama akurasi juga menunjukkan pada rentang lumayan yaitu mendekati nilai 1.0


Informasi Course Terkait
Kategori: Data Science / Big DataCourse: Speech Classification Menggunakan Machine Learning



