
Simple Big Data Analysis with PySpark
RENDIKA NURHARTANTO SUHARTO



Summary
Portfolio ini dibuat untuk memberikan pemahaman tentang PySpark, yang mencakup analisis data, EDA (Exploratory Data Analysis), dan visualisasi data. PySpark merupakan antarmuka Python yang memungkinkan pengguna berinteraksi dengan Apache Spark, sebuah kerangka kerja pemrosesan data yang terdistribusi. Dengan menggunakan Python, pengguna dapat membuat, mengelola, dan mentransformasikan DataFrames dan RDDs di Spark. Ini memungkinkan pemrosesan data dalam skala besar dengan kinerja tinggi melalui sistem terdistribusi. PySpark memanfaatkan fitur-fitur Spark seperti pemrosesan batch, aliran (streaming), pembelajaran mesin (machine learning), dan pemrosesan grafik. Integrasi yang baik dengan ekosistem Python memungkinkan pengguna memanfaatkan alat dan pustaka Python yang sudah ada untuk analisis data. Oleh karena itu, PySpark menjadi pilihan yang populer untuk analisis data skala besar dalam lingkungan Python.
Description
Big data merujuk pada dataset yang besar dan kompleks, di mana metode pemrosesan data tradisional tidak lagi cukup untuk menganalisis dan menginterpretasi informasi yang terkandung di dalamnya. Untuk memahami dan mengatasi tantangan big data, dikenal dengan konsep 5V: Volume (jumlah data yang besar), Variety (ragam jenis data), Velocity (kecepatan pertukaran data), Value (nilai atau makna data), dan Veracity (kepastian atau keandalan data). Melalui kursus ini, kita akan belajar bagaimana menganalisis data menggunakan PySpark, sebuah library yang dirancang khusus untuk menangani kompleksitas big data. pada portofolio ini akan menunjukkan pengaplikasiannya dalam sebuah dataset “Data Science Job Salaries”.
Let's Code PySpark
 |  |
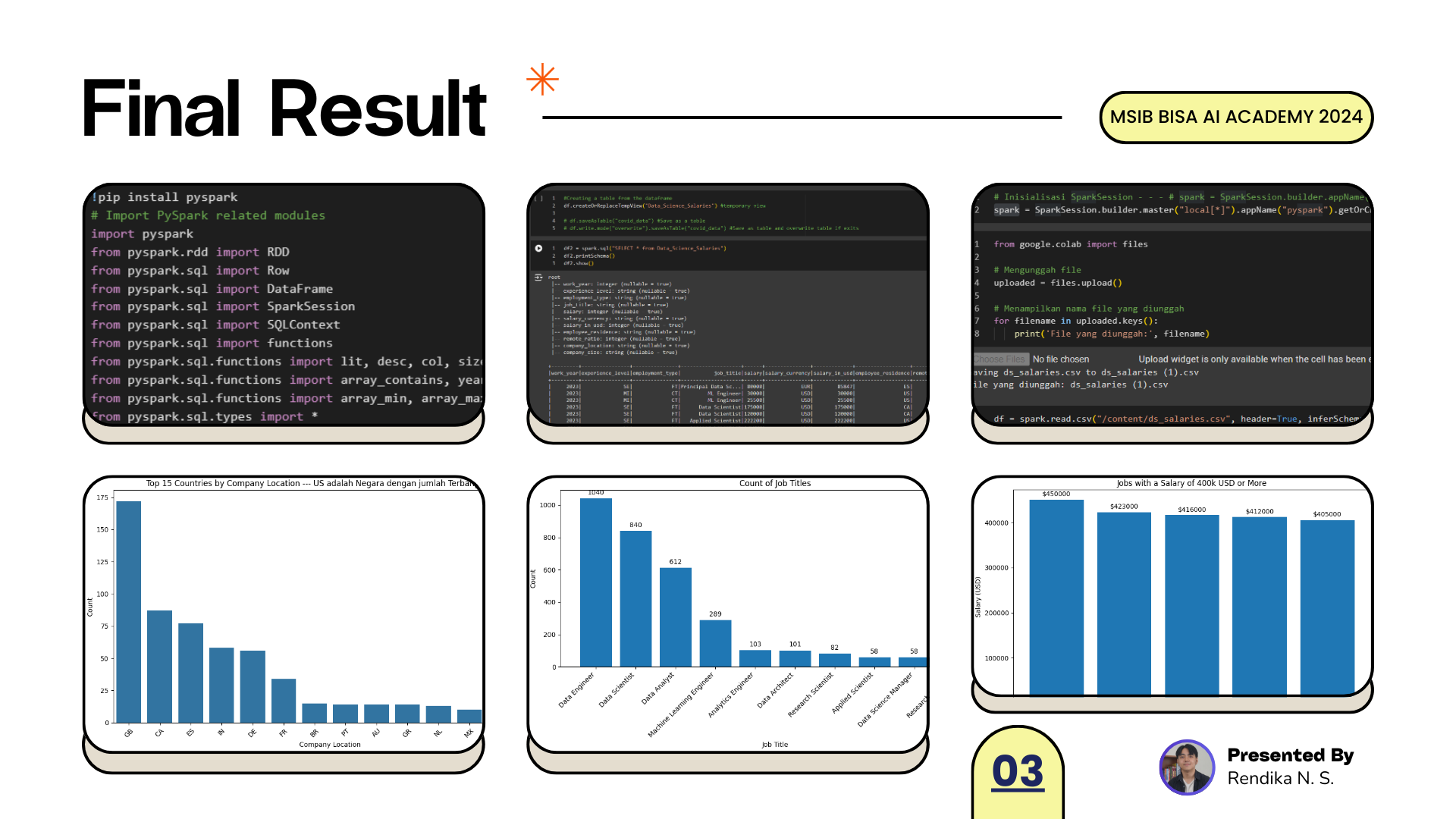
Pertama, langkah awal adalah melakukan instalasi PySpark melalui perintah !pip install pyspark, memastikan bahwa kita memiliki akses ke semua fungsi dan fitur yang disediakan olehnya. Setelah itu, modul-modul yang diperlukan diimpor ke dalam skrip Python, seperti RDD, DataFrame, dan fungsi-fungsi bawaan PySpark. Selanjutnya, SparkSession diinisialisasi, yang berperan sebagai titik masuk utama untuk berinteraksi dengan DataFrame dan menjalankan operasi SQL. Terakhir, dengan menggunakan fungsi-fungsi bawaan PySpark dan tipe data yang disediakan, kita dapat melakukan berbagai operasi transformasi dan manipulasi data dalam DataFrame. Dengan tahapan ini, kita siap untuk memulai analisis dan pengolahan data menggunakan PySpark. Lalu setelah tahap ini, seperti biasa akan dilakukan import library pada umumnya yang akan diperlukan, seperti Numpy, Pandas, Matplotlib, Seaborn, Os, request, dan lain seperti tertampil disebelah kanan ini.

Pada code diatas dilakukan konfigurasi kaggle dan fetching dataset from kaggle menggunakan kaggle API, lalu data akan disave pada path yang diinginkan, setelahnya file berbentuk zip di unzip dan dihapuskan agar tidak membuang resource storage pada Google Drive.

Perintah SparkSession.builder.master("local[*]").appName("pyspark").getOrCreate() digunakan untuk membuat atau mengambil sesi Spark. Ini adalah langkah penting dalam memulai penggunaan PySpark. SparkSession.builder: Ini adalah objek builder yang digunakan untuk mengonfigurasi sesi Spark. master("local[*]"): Parameter master menentukan URL master Spark, dalam hal ini "local[*]" digunakan untuk menjalankan Spark dalam mode lokal dengan menggunakan semua core CPU yang tersedia. appName("pyspark"): Parameter appName digunakan untuk memberikan nama aplikasi kepada sesi Spark yang akan dibuat. Dalam hal ini, nama aplikasi yang diberikan adalah "pyspark". getOrCreate(): Metode getOrCreate() digunakan untuk membuat sesi Spark baru jika belum ada, atau mengambil sesi yang sudah ada jika telah dibuat sebelumnya.

Potongan kode di atas digunakan untuk mengunggah file dari sistem lokal ke sesi Google Colab dan membaca file CSV yang diunggah ke dalam DataFrame Spark. Pertama import Modul: Mengimpor modul files dari pustaka google.colab untuk mengelola pengunggahan file. Mengunggah File: Pengguna diminta untuk mengunggah file dari sistem lokal mereka ke sesi Google Colab menggunakan files.upload(). Setelah diunggah, file tersebut akan disimpan dalam objek uploaded. Menampilkan Nama File: Nama file yang diunggah kemudian ditampilkan menggunakan perulangan for. Membaca File CSV: DataFrame Spark dibuat dengan menggunakan spark.read.csv(), di mana file CSV yang diunggah dibaca dan dimuat ke dalam DataFrame. Argumen header=True digunakan untuk menunjukkan bahwa file CSV memiliki baris header, sedangkan inferSchema=True digunakan untuk mengaktifkan inferensi skema otomatis oleh Spark.
Spark Simple SQL Query

Perintah df.createOrReplaceTempView("Data_Science_Salaries") digunakan untuk membuat tampilan tabel sementara (temporary view) yang dapat diakses menggunakan SQL di dalam sesi Spark. Tampilan sementara ini memungkinkan penggunaan bahasa SQL untuk menjalankan kueri terhadap DataFrame Spark. Dalam kasus ini, tampilan sementara dinamai "Data_Science_Salaries".


Potongan kode di atas digunakan untuk menjalankan kueri SQL pada tampilan sementara yang telah dibuat sebelumnya dan menampilkan hasilnya. spark.sql("SELECT * from Data_Science_Salaries"): Ini adalah perintah untuk menjalankan kueri SQL yang memilih semua kolom dari tampilan sementara "Data_Science_Salaries". df2.printSchema(): Ini mencetak skema DataFrame df2, yang berisi informasi tentang nama kolom dan tipe data masing-masing. df2.show(): Ini menampilkan isi DataFrame df2, yang merupakan hasil dari kueri SQL yang dijalankan sebelumnya. Hasilnya akan menampilkan beberapa baris data dari tampilan sementara "Data_Science_Salaries".

|  |
Perintah diatas adalah spark.sql("SELECT job_title, count(*) as job_count FROM Data_Science_Salaries GROUP BY job_title") yang berarti perintah SQL untuk mengelompokkan data dalam tampilan sementara "Data_Science_Salaries" berdasarkan judul pekerjaan (job_title) dan menghitung jumlah masing-masing judul pekerjaan. Hasilnya disimpan dalam DataFrame baru yang disebut groupDF. groupDF.orderBy("job_count", ascending=False): Ini adalah perintah untuk mengurutkan DataFrame groupDF berdasarkan kolom "job_count" secara menurun (descending). Dengan kata lain, judul pekerjaan dengan jumlah pekerjaan terbanyak akan muncul teratas. sorted_groupDF.show(): Ini menampilkan DataFrame hasil pengurutan, yang akan menampilkan judul pekerjaan dan jumlah pekerjaan yang terkait, diurutkan dari jumlah pekerjaan terbanyak hingga jumlah pekerjaan terendah.
PySpark Implementation

Potongan kode di atas digunakan untuk memilih kolom 'job_title' dan 'salary' dari DataFrame Spark yang disebut df, dan kemudian menampilkan lima baris pertama dari hasil pemilihan. df.select('job_title', 'salary'): Ini adalah perintah untuk memilih dua kolom dari DataFrame df, yaitu 'job_title' (judul pekerjaan) dan 'salary' (gaji), yang akan menjadi output dari operasi pemilihan. .show(5): Ini adalah perintah untuk menampilkan lima baris pertama dari hasil pemilihan tersebut.

df.describe(): Ini adalah metode untuk menghasilkan statistik deskriptif seperti count (jumlah data), mean (rata-rata), stddev (standar deviasi), min (nilai minimum), dan max (nilai maksimum) untuk semua kolom numerik dalam DataFrame. Metode ini secara otomatis mengabaikan kolom non-numerik.

Pada tahap ini dilakukan penambahan kolom baru pada dataset sebagaimana penerapan Feature Engineering pada umumnya yaitu menambahkan feature baru dair feature yang sudah ada sebelumnya. Penghitungan Tahun Pengalaman Kerja: Baris pertama current_year = 2024 menetapkan nilai tahun saat ini. Kemudian, df.withColumn("work_experience", current_year - col("work_year")) digunakan untuk menambahkan kolom baru yang disebut "work_experience". Nilai dalam kolom ini adalah selisih antara tahun kerja saat ini (diberikan oleh current_year) dan tahun kerja yang terdapat dalam kolom "work_year". Kategori Remote: Baris pertama menentukan kategori remote berdasarkan nilai dalam kolom "remote_ratio". Jika nilai tersebut adalah 100, maka kategori remote dianggap sebagai "Full Remote". Jika nilai tersebut lebih dari 0, maka kategori remote dianggap sebagai "Partial-Remote". Jika kedua kondisi sebelumnya tidak terpenuhi, maka kategori remote dianggap sebagai "On-Site". Hasilnya ditambahkan ke kolom baru yang disebut "remote_category".


df.toPandas(): Ini adalah metode yang digunakan untuk mengonversi DataFrame Spark menjadi DataFrame Pandas Konversi ini dilakukan untuk mempermudah kita dalam memanipulasi, dan memvisualisasikan data dengan tetap menggunakan dataframe dari pandas. Namun pada portofolio ini hanya ingin menunjukkan cara penggunaannya saja, tidak akan digunakan dataframe dari pandas. Gambar atas adalah hasil konversi kedalam bentuk pandas, dan baawah adalah bentuk dataframe spark.
EDA (Exploratory Data Analysis)

Filtering: Baris pertama filtered_df_1 = df.filter((df["salary"] > 400000) & (df["salary_currency"] == "USD")) mengaplikasikan filter untuk memilih baris-baris di mana gajinya lebih besar dari 400,000 dan mata uangnya adalah USD. Hasil dari filter ini disimpan dalam DataFrame baru yang disebut filtered_df_1. Sorting: Baris kedua sorted_df_1 = filtered_df_1.orderBy(df["salary"].desc()).select("job_title","salary") mengurutkan DataFrame filtered_df_1 berdasarkan kolom "salary" secara descending (dari yang tertinggi ke terendah). Kemudian, hanya kolom "job_title" dan "salary" yang dipilih dari DataFrame yang diurutkan. Hasil dari operasi ini disimpan dalam DataFrame baru yang disebut sorted_df_1. Menampilkan Data: Baris terakhir sorted_df_1.show() digunakan untuk menampilkan hasil dari DataFrame yang sudah diurutkan. Ini akan menampilkan job title dan salary dari baris-baris yang memenuhi kriteria filter dan diurutkan. Dibawah ini adalah hasil plotnya kedalam grafik batang.

|  |

Menghitung Jumlah Pekerjaan Yang Paling banyak Muncul: Dengan menggunakan fungsi SQL SELECT job_title, count(*) as job_count FROM Data_Science_Salaries GROUP BY job_title, kode tersebut menghitung jumlah pekerjaan untuk setiap judul pekerjaan yang ada dalam DataFrame. Hasilnya disimpan dalam DataFrame Pandas baru yang disebut filtered_df_2. Lalu selanjutnya adalah Mengurutkan dan Memilih 10 Pekerjaan Teratas: DataFrame filtered_df_2 kemudian diurutkan berdasarkan jumlah pekerjaan (job_count) secara menurun (descending order) menggunakan metode sort_values(by='job_count', ascending=False). Setelah diurutkan, kode tersebut memilih 10 baris teratas menggunakan fungsi head(10). Hasilnya disimpan dalam DataFrame Pandas baru yang disebut top_10_jobs.


Menghitung Jumlah Perusahaan: Dengan menggunakan fungsi SQL SELECT company_location, company_size, count(*) as company_count FROM Data_Science_Salaries GROUP BY company_location, company_size, kode tersebut menghitung jumlah perusahaan untuk setiap lokasi dan ukuran perusahaan dalam DataFrame. Hasilnya disimpan dalam DataFrame baru. Mengurutkan Hasil: Hasil dari penghitungan tersebut kemudian diurutkan berdasarkan kolom company_location, company_size, dan company_count secara berurutan menggunakan klausa ORDER BY.

Jadi disini hasilnya adalah Company Location dimana berisi kode sebuah Negara, dan company_size berisikan L, M, dan S yaitu Large, Medium, dan Small. terakhir adalah company_count berisikan berapa banyak company yang ada. dapat disimpulkan seperti ini “pada negara AE terdapat 1 buah company dengan size large dan 2 company dengan size small” dan masih banyak lagi insight yang bisa didapatkan.

Menghitung Jumlah Perusahaan Berdasarkan Lokasi: Dengan menggunakan fungsi SQL SELECT company_location, count(*) as company_location_count FROM Data_Science_Salaries GROUP BY company_location, kode tersebut menghitung jumlah perusahaan untuk setiap lokasi dalam DataFrame. Hasilnya disimpan dalam DataFrame baru. Mengurutkan dan Memilih 15 Negara Teratas: Hasil dari penghitungan tersebut kemudian diurutkan berdasarkan jumlah perusahaan dalam setiap lokasi secara menurun menggunakan klausa ORDER BY dan dipilih 15 negara teratas dengan menggunakan fungsi head(15). Data tersebut kemudian direset indeksnya agar dimulai dari 0. Disini menggunakan manipulasi tambahan yaitu top_15_countires_pakai karena ingin skip nomor pertama disebabkan ketimpangan jumlah membuat grafik tidak dapat di telaah dengan baik dan visual pun buruk. Beginilah pada bagian visualisasi-nya.


Informasi Course Terkait
Kategori: Data Science / Big DataCourse: Big Data Analytics dengan PySpark



