
Image Classification CIFAR-10 Using VGG-16
RENDIKA NURHARTANTO SUHARTO



Summary
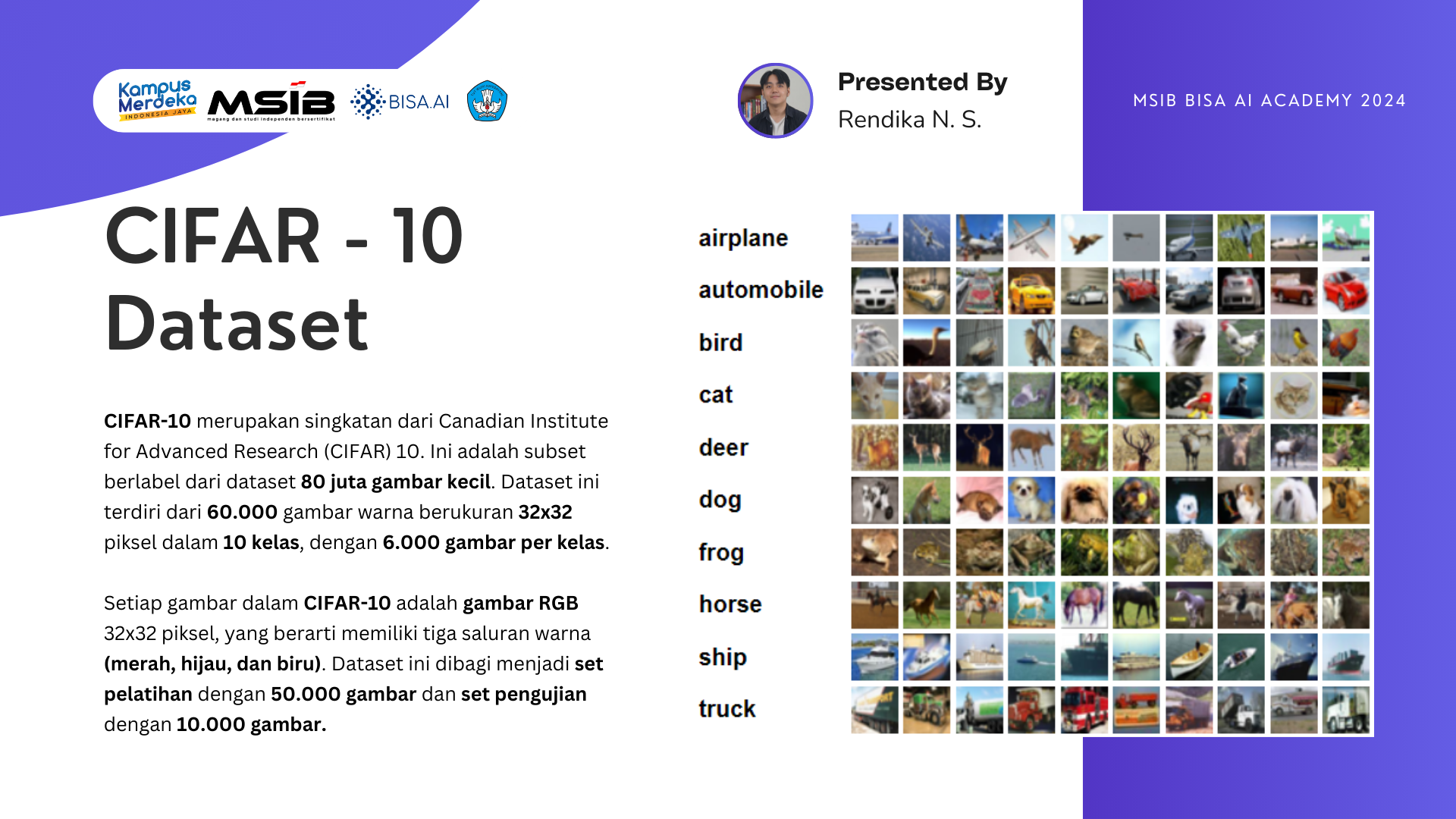
Proyek ini bertujuan untuk membuat model klasifikasi yang mampu memprediksi lebih dari dua kelas (bukan biner). Dataset yang digunakan adalah CIFAR-10 yang terdiri dari sepuluh kelas, dan pendekatan yang diambil menggunakan arsitektur model CNN VGG16. Langkah-langkah yang dilakukan mencakup augmentasi gambar, normalisasi data, serta pengkodean one-hot encoding (OHE) pada labelnya, lalu pelatihan model, dan evaluasi model, serta terakhir adalah prediction image.
Description
Image processing merupakan pemrosesan data citra yang menggunakan computer supaya menjadi citra yang kualitasnya lebih baik. Sebagai contoh Citra yang terdapat noise, supaya mudah diinterpretasi (baik oleh manusia maupun mesin), maka citra tersebut perlu dimanipulasi menjadi citra lain yang kualitasnya menjadi lebih baik. Salah satu library untuk manipulasi data citra adalah menggunakan library OpenCV. Pengguna dapat memilih metode sesuai kebutuhan menggunakan library ini.
Jadi, dengan pemrosesan citra menggunakan OpenCV, Anda dapat meningkatkan kualitas citra Anda dengan menghilangkan noise atau memperbaiki masalah lainnya yang dapat mengganggu proses klasifikasi. Setelah Anda memproses citra, Anda dapat menggunakan dataset CIFAR-10 untuk melatih model klasifikasi gambar.
Dataset CIFAR-10 adalah dataset populer yang terdiri dari 60.000 gambar berwarna dengan resolusi 32x32, yang terbagi menjadi 10 kelas. Setiap kelas memiliki 6.000 gambar. Ini termasuk gambar-gambar objek seperti mobil, pesawat, anjing, kucing, dan lainnya. Klasifikasi gambar dengan dataset ini adalah tugas umum dalam pemrosesan citra dan pembelajaran mesin.
Dengan menggabungkan pemrosesan citra menggunakan OpenCV dan klasifikasi gambar dengan dataset CIFAR-10, Anda dapat membuat sistem yang mampu mengenali objek dalam gambar dengan akurasi tinggi. Ini bisa memiliki banyak aplikasi, mulai dari pengenalan objek otomatis hingga pengawasan keamanan. Jadi, dengan dasar yang Anda miliki, Anda sudah siap untuk mengeksplorasi dan membangun model klasifikasi gambar yang kuat!
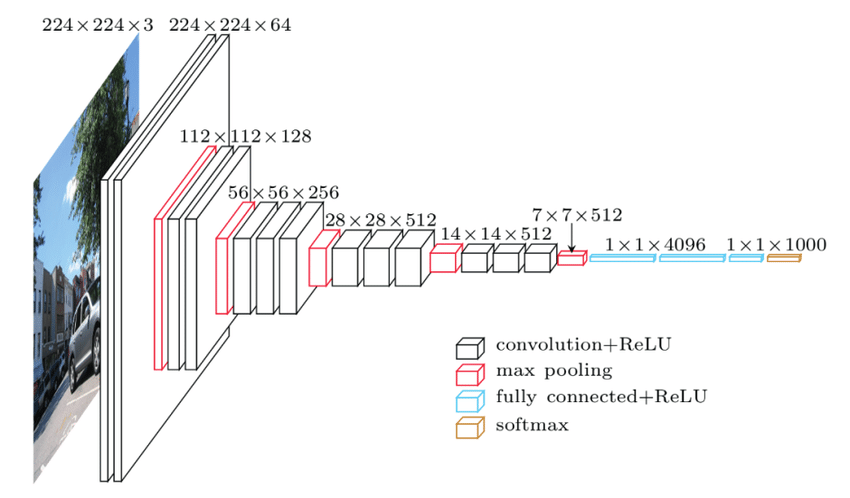 |  |
Gambar 1. (Kiri) Visual Arsitektur original from website ; (Kanan) Visualisasi menggunakan visualkeras.layered_view
Pada project ini digunakan model CNN dengan Arsitektur VGG-16, yang menampilkan beberapa Convolution Layer diikuti oleh lapisan Max_Pooling dan lapisan Dropout, serta lapisan yang terhubung sepenuhnya untuk klasifikasi. Ini dimulai dengan memasangkan lapisan Conv2D dengan 32 filter ukuran 3x3, diikuti oleh Batch Normalization untuk regularisasi dan mempercepat pelatihan serta membantu mencegah overfitting. Lapisan MaxPooling2D mengurangi dimensi spasial, diikuti oleh lapisan Dropout untuk mencegah overfitting. Pola ini berulang dengan meningkatnya filter (32, 64, 128, 256) dan tingkat dropout (0,2 hingga 0,5). Setelah lapisan konvolusional dan Pooling, lapisan Ratakan mengubah keluaran menjadi vektor 1D, diikuti oleh Dense (or fully connected) layer dengan 10 unit untuk klasifikasi menggunakan aktivasi softmax. Teknik regularisasi seperti regularisasi L2, Dropout, dan Batch Normalization digunakan untuk efisiensi dan kesederhanaan, dengan fokus pada pembelajaran fitur hierarki dari gambar CIFAR-10 sekaligus mencegah overfitting. Namun meskipun terinspirasi oleh VGG16, model ini tetap sederhana dan tidak menggabungkan fitur-fitur canggih dari arsitektur terkini, melainkan berfokus pada efisiensi dan kesederhanaan.
LET'S JUMP TO THE CODE :
1. Import Library Needed

Library yang digunakan adalah visualkeras, tensorflow, warnings, numpy, matplotlib, sklearn, keras. semua memiliki fungsinya masing masing. misalkan numpy adalah untuk proses aritmatika dan manipulsai data numerik pada python, matplotlib dan bisa saja menggunakan seaborn untuk library visualisasi data, lalu warnings untuk menghilangkan peringatan peringatan yang menggangu saat code dijalankan, tensorflow, keras dan sklearn adalah library yang sering digunakan untuk pembuatan model machine learning dan deep learning.
2. Load CIFAR-10 dataset


Load data dilakukan dengan menggunakan library dari tensorflow dataset, lalu dipisah menjadi train, test, dan validation set. setelahnya dilakukan pengecekan untuk jumlah data, apakah sudah sesuai atau tidak contohnya seperti gambar diatas.
3. Data Preview


4. Preprocess the data

Kode di atas adalah contoh dari beberapa teknik preprocessing umum yang digunakan dalam pembelajaran mesin, terutama pada tugas klasifikasi gambar seperti dataset CIFAR-10. Pertama, kita melihat dua metode normalisasi yang umum digunakan: simple feature scaling (SFS) dan z-score.
Metode simple feature scaling mengubah nilai piksel menjadi rentang antara 0 dan 1 dengan membagi setiap nilai piksel dengan nilai maksimumnya, dalam hal ini adalah 255. Ini menghasilkan representasi data yang ternormalisasi dalam rentang yang konsisten.
Metode z-score, di sisi lain, melakukan normalisasi berdasarkan nilai rata-rata dan standar deviasi data. Dalam kode ini, nilai piksel dari setiap gambar dinormalisasi dengan mengurangi rata-rata dari seluruh dataset dan kemudian dibagi dengan standar deviasi, sehingga menghasilkan distribusi yang memiliki rata-rata nol dan standar deviasi satu.
Selanjutnya, kita memiliki langkah One Hot Encoding (OHE) untuk label. Ini mengubah label kelas menjadi vektor biner, di mana hanya satu elemen dari vektor yang bernilai 1, yang mewakili kelas yang tepat, sedangkan yang lainnya adalah 0. Hal ini penting untuk mendukung proses pelatihan model klasifikasi yang menggunakan output softmax, di mana model menghasilkan probabilitas untuk setiap kelas.
Dengan menggunakan teknik-teknik ini, data siap untuk digunakan dalam pelatihan model klasifikasi gambar seperti Convolutional Neural Network (CNN) untuk mengklasifikasikan gambar-gambar dari dataset CIFAR-10.
5. Data Augmentation

Kode tersebut menggunakan ImageDataGenerator dari Keras untuk menerapkan augmentasi data pada dataset gambar. Augmentasi data adalah teknik yang penting dalam pelatihan model machine learning, terutama pada tugas klasifikasi gambar, karena memperkaya variasi data pelatihan dengan mengubah gambar-gambar asli secara acak. Ini membantu model untuk belajar pola-pola yang lebih umum dan meningkatkan kemampuannya dalam menggeneralisasi pada data baru yang belum pernah dilihat sebelumnya. Dengan berbagai parameter seperti rotasi, pergeseran, pembalikan, dan lain-lain, augmentasi data membantu mencegah overfitting dan meningkatkan kinerja model pada beragam situasi gambar.
6. Build The Model VGG-16 Architecture

Arsitektur model terinspirasi oleh jaringan VGG16, yang menampilkan beberapa Convolution Layer diikuti oleh lapisan Max_Pooling dan lapisan Dropout, serta lapisan yang terhubung sepenuhnya untuk klasifikasi. Ini dimulai dengan memasangkan lapisan Conv2D dengan 32 filter ukuran 3x3, diikuti oleh Batch Normalization untuk regularisasi dan mempercepat pelatihan serta membantu mencegah overfitting. Lapisan MaxPooling2D mengurangi dimensi spasial, diikuti oleh lapisan Dropout untuk mencegah overfitting. Pola ini berulang dengan meningkatnya filter (32, 64, 128, 256) dan tingkat dropout (0,2 hingga 0,5). Setelah lapisan konvolusional dan Pooling, lapisan Ratakan mengubah keluaran menjadi vektor 1D, diikuti oleh Dense (or fully connected) layer dengan 10 unit untuk klasifikasi menggunakan aktivasi softmax. Teknik regularisasi seperti regularisasi L2, Dropout, dan Batch Normalization digunakan untuk efisiensi dan kesederhanaan, dengan fokus pada pembelajaran fitur hierarki dari gambar CIFAR-10 sekaligus mencegah overfitting. Namun meskipun terinspirasi oleh VGG16, model ini tetap sederhana dan tidak menggabungkan fitur-fitur canggih dari arsitektur terkini, melainkan berfokus pada efisiensi dan kesederhanaan.
Model kita hanya terdiri dari 1.186.346 parameter, 1.184.426 di antaranya dapat dilatih. Ini adalah model yang relatif kompak, terutama jika dibandingkan dengan arsitektur canggih yang sering kali memiliki puluhan atau bahkan ratusan juta parameter.
Parameter-parameter yang "trainable" dalam sebuah model jaringan saraf adalah parameter-parameter yang disesuaikan selama proses pelatihan untuk meminimalkan fungsi kerugian dan meningkatkan kinerja model. Ini termasuk bobot (weights) dari lapisan-lapisan Conv2D dan Dense, bias, parameter-parameter BatchNormalization yang diatur sebagai trainable, dan parameter-parameter regularisasi. Di sisi lain, parameter-parameter yang "tidak trainable" biasanya terkait dengan lapisan-lapisan khusus seperti lapisan BatchNormalization yang mungkin memiliki parameter "scale" dan "center" yang tidak diatur sebagai trainable untuk tujuan tertentu, atau parameter-parameter yang disetel statis seperti dalam beberapa konfigurasi praproses data atau lapisan-lapisan khusus yang tidak memerlukan penyesuaian selama pelatihan.
7. Training model VGG-16

Sekarang adalah proses pelatihan model jaringan saraf. Proses pelatihan ini menggunakan ukuran batch sebesar 64 dan akan berjalan maksimal selama 250 epoch atau hingga kriteria EarlyStopping terpenuhi. Selama pelatihan, kinerja model dievaluasi pada data validasi setelah setiap epoch. Untuk mengoptimalkan proses pelatihan, saya telah menyertakan dua callback function:
Fungsi panggilan ReduceLROnPlateau menyesuaikan learning rate secara dinamis, dengan mengurangi separuhnya (faktor=0.5) ketika loss_validation tidak mengalami perbaikan selama 10 epoch berturut-turut. Penyesuaian ini membantu model untuk mendekati nilai minimum global dari loss_function saat kemajuan terhenti, yang dapat meningkatkan konvergensi pelatihan.
Fungsi panggilan EarlyStopping memantau loss_validation dan menghentikan proses pelatihan jika tidak ada peningkatan selama jumlah epoch yang telah ditentukan. Hal ini mencegah penggunaan sumber daya dan waktu yang tidak perlu. Selain itu, fungsi panggilan ini mengembalikan bobot terbaik yang diperoleh selama pelatihan, sehingga kami dapat mempertahankan konfigurasi model yang optimal.
8. Evaluasi Model






9. Model Inference

 |  |  |
Informasi Course Terkait
Kategori: Computer VisionCourse: Image Processing with OpenCV



