
Implementasi HPC Pada Perkalian Matriks
Imtiyas Azzahra

Summary
Metode eliminasi perkalian pada matriks umumnya terbagi atas dua, yaitu Metode eliminasi Gauss dan Metode eliminasi Gauss Jordan. Metode eliminasi Gauss Jordan adalah perluasan dari metode eliminasi Gauss. Metode ini mengubah matriks menjadi bentuk eselon tereduksi, di mana setiap elemen diagonal utama adalah 1 dan setiap kolom di atas dan di bawah elemen diagonal utama berisi semua nol. Sedangkan MPI merupakan salah satu algoritma dari metode perkalian pada matriks yang termasuk kedalam Metode perkalian matriks paralel. Metode ini memanfaatkan pemrosesan paralel untuk mempercepat perkalian matriks.MPI (Message Passing Interface) pada High-Performance Computing (HPC), matriks dapat dibagi menjadi blok-blok yang diolah oleh beberapa prosesor secara bersamaan. Metode perkalian matriks paralel ini memungkinkan distribusi beban kerja dan komputasi paralel yang efisien.
Description
Langkah manual eliminasi Gauss-Jordan:
- Menggunakan operasi baris dasar untuk menghasilkan nol di bawah dan di atas elemen diagonal utama pada setiap langkah
- Menggunakan operasi baris dasar tambahan untuk mengubah elemen diagonal utama menjadi 1 dengan membagi setiap baris dengan elemen diagonal utamanya
Listing program:
from mpi4py import MPI
import numpy as np
comm = MPI.COMM_WORLD
rank = comm.Get_rank()
size = comm.Get_size()
n = 1000
if rank == 0:
A = np.random.rand(n, n)
B = np.random.rand(n, 1)
else:
A = None
B = None
B = comm.bcast(B, root=0)
A_block = np.zeros((n, n // size))
comm.Scatter(A, A_block, root=0)
for k in range(n):
pivot = A_block[k, k]
for j in range(k, n // size):
A_block[k, j] /= pivot
B[k] /= pivot
comm.Bcast(A_block[k, :], root=k % size)
for i in range(k + 1, n // size):
factor = A_block[i, k]
for j in range(k + 1, n // size):
A_block[i, j] -= factor * A_block[k, j]
B[i] -= factor * B[k]
A_new = None
if rank == 0:
A_new = np.zeros((n, n))
A_new_block = np.zeros((n, n // size))
comm.Gather(A_block, A_new_block, root=0)
if rank == 0:
for i in range(size):
A_new[:, i * (n // size):(i + 1) * (n // size)] = A_new_block[:, i * (n // size):(i + 1) * (n // size)]
B_new = None
if rank == 0:
B_new = np.zeros((n, 1))
comm.Gather(B, B_new, root=0)
if rank == 0:
x = np.linalg.solve(A_new, B_new)
print("Hasil x:")
print(x)
Penjelasan listing program:
from mpi4py import MPI input library yang dibutuhkan
import numpy as np input library yang dibutuhkan
Inisialisasi MPI
comm = MPI.COMM_WORLD objek komunikator MPI
rank = comm.Get_rank() mendapatkan rank (peringkat) prosesor saat ini dalam komunikator
size = comm.Get_size() mendapatkan jumlah total prosesor dalam komunikator
Membuat matriks ukuran n x n
n = 1000 input default ukuran matriks, baris sebanyak 1000 dan kolom sebanyak 1000
Membuat matriks secara acak
if rank == 0: rank 0 sering digunakan sebagai prosesor master atau koordinator dalam implementasi MPI
A = np.random.rand(n, n)
B = np.random.rand(n, 1)
else:
A = None
B = None
Broadcast matriks B ke semua prosesor
B = comm.bcast(B, root=0) melakukan operasi broadcast pada data di dalam komunikator
Memecah matriks A menjadi blok
A_block = np.zeros((n, n // size)) membuat matriks dengan ukuran baris = n dan kolomnya == n // size
A_block = np.zeros((n, n // size)) dengan size adalah jumlah total prosesor dalam komunikator MPI
comm.Scatter(A, A_block, root=0) membagi matriks A dari prosesor dengan rank 0 menjadi blok kecil
comm.Scatter(A, A_block, root=0) dan mendistribusikan blok-blok tersebut ke setiap prosesor dalam komunikator
Eliminasi Gauss Jordan
for k in range(n):
pivot = A_block[k, k]
for j in range(k, n // size):
A_block[k, j] /= pivot
B[k] /= pivot
comm.Bcast(A_block[k, :], root=k % size)
for i in range(k + 1, n // size):
factor = A_block[i, k]
for j in range(k + 1, n // size):
A_block[i, j] -= factor * A_block[k, j]
B[i] -= factor * B[k]
Mengumpulkan blok A yang sudah dieliminasi
A_new = None
if rank == 0:
A_new = np.zeros((n, n))
A_new_block = np.zeros((n, n // size))
comm.Gather(A_block, A_new_block, root=0)
if rank == 0:
for i in range(size):
A_new[:, i * (n // size):(i + 1) * (n // size)] = A_new_block[:, i * (n // size):(i + 1) * (n // size)]
Mengumpulkan hasil B yang sudah dieliminasi
B_new = None
if rank == 0:
B_new = np.zeros((n, 1))
comm.Gather(B, B_new, root=0)
Output hasil
if rank == 0:
x = np.linalg.solve(A_new, B_new)
print("Hasil x:")
print(x)
Algoritma pembuatan matriks lainnya:
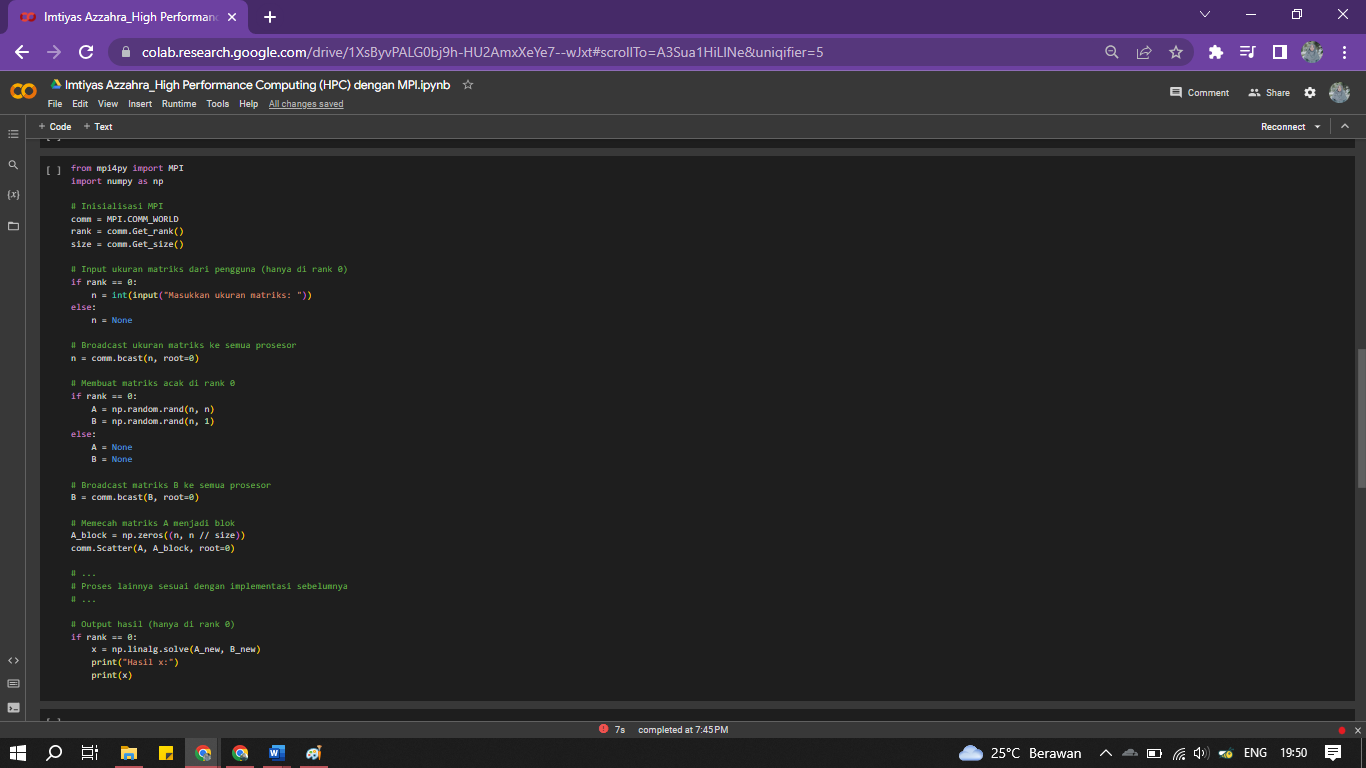
- User Input dengan jumlah baris dan kolom tergabung
Membuat matriks ukuran n x n dengan input dari pengguna
if rank == 0:
n = int(input("Masukkan ukuran matriks: "))
else:
n = None
Broadcast ukuran matriks ke semua prosesor
n = comm.bcast(n, root=0)
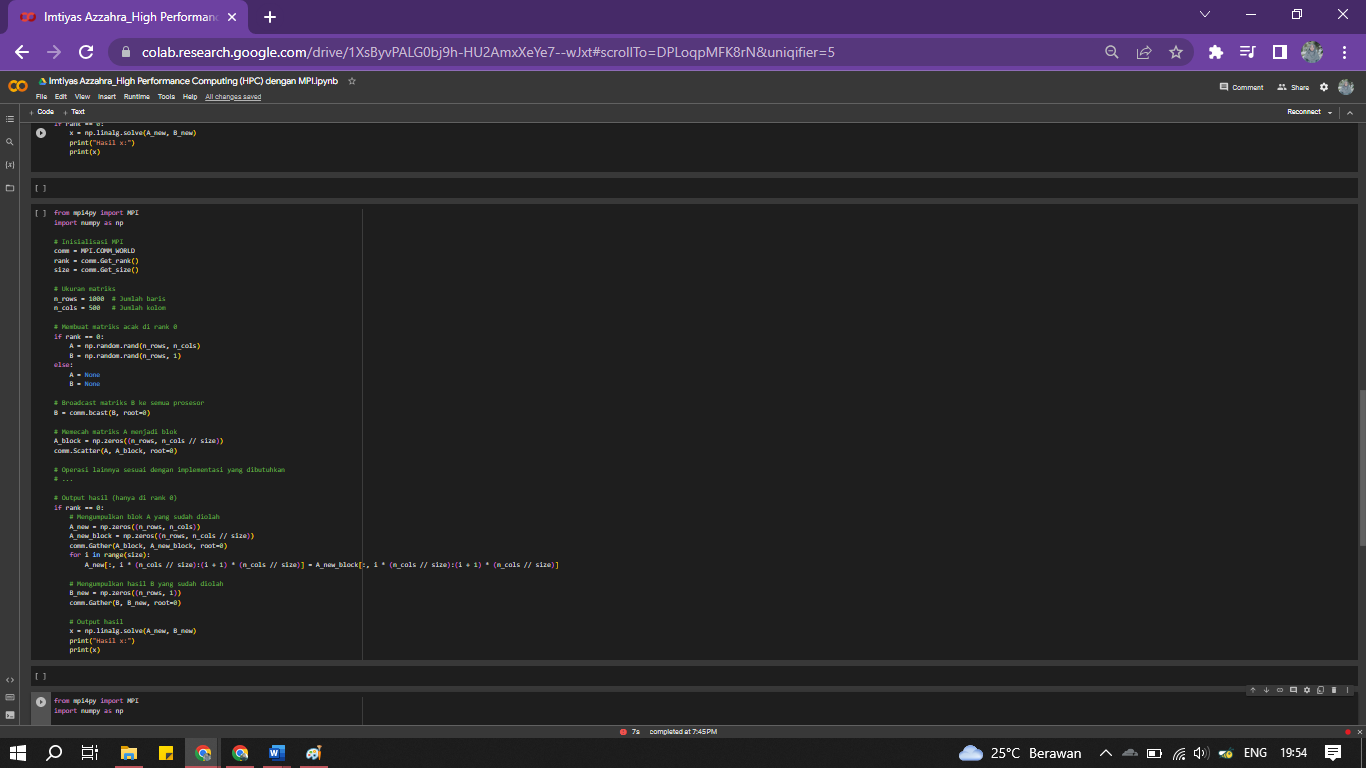
- Nilai default dengan jumlah baris dan kolom terpisah
Membuat matriks ukuran n_rows x n_cols
n_rows = 1000 Jumlah baris
n_cols = 500 Jumlah kolom
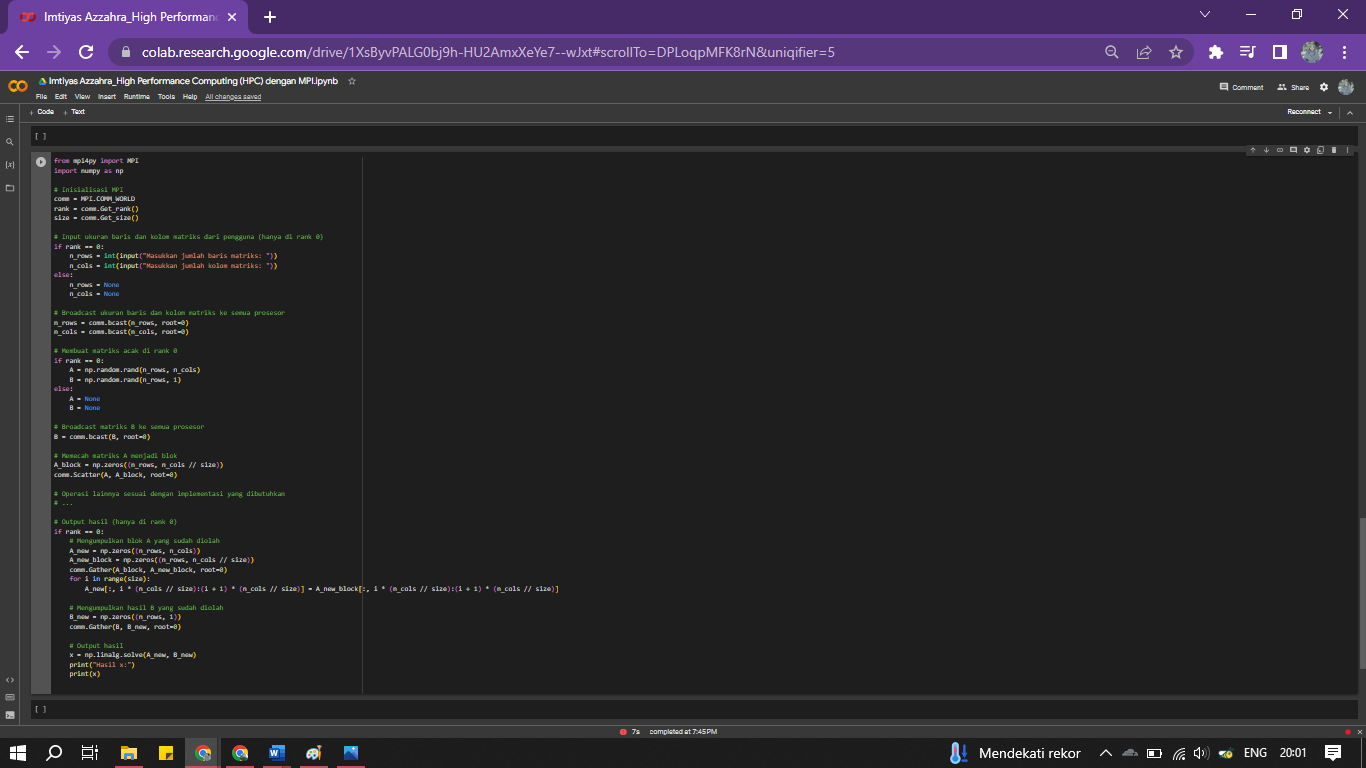
- User Input dengan jumlah baris dan kolom terpisah
Membuat matriks ukuran n_rows x n_cols dengan input dari pengguna
if rank == 0:
n_rows = int(input("Masukkan jumlah baris matriks: "))
n_cols = int(input("Masukkan jumlah kolom matriks: "))
else:
n_rows = None
n_cols = None
Broadcast ukuran baris dan kolom matriks ke semua prosesor
n_rows = comm.bcast(n_rows, root=0)
n_cols = comm.bcast(n_cols, root=0)
Informasi Course Terkait
Kategori: Data Science / Big DataCourse: High Performance Computing (HPC) dengan MPI



